Outils de Traitement de Corpus
Cours d'Outils de traitement de Corpus - PluriTAL
Project maintained by EveSa Hosted on GitHub Pages — Theme by mattgraham
Outils de Traitement de Corpus
cours 2 -vertical-
Rappel du cours précédent
Rappels sur les corpus
Focus sur les tâches
Les types de données
Où trouver des corpus
-vertical-
-vertical-
Présentation des nouvelles
-horizontal-
Cours 2
Collecter les données
-vertical-
Pourquoi collecter des données ?
- Des données spécifiques
- de tâches
- de domaine
- des données confidentielles (médicale, nucléaire)
-vertical-
La qualité des modèles = la qualité des données
Les modèles vont apprendre à généraliser sur les données présente dans le corpus d’entraînement.
Sans données, les modèles neuronaux n’existent pas (contrairement aux modèles de règles par exemple).
-vertical-
Comment récupérer des bonnes données ?
- Eviter les biais :
- récupérer des données variées
- Eviter les données manquantes
- Récupérer suffisemment de données
-vertical-
Considérations éthiques
Des lois existent pour protéger les données sur le web :
- les licences
- La RGPD
-vertical-
Récupérer des données
Depuis des bases préexistantes
Depuis une API
Depuis le web
Stocker les données
-vertical-
Depuis des base pré-existantes
On peut utiliser des bases stockées sur des serveurs
→ qu’est ce qu’un serveur ?
Pour cela on va devoir requêter les bases avec un Système de Gestion de base de Données (SGBD) type SQL, ou Mongo.
-vertical-
Avec python,
On va pouvoir connecter sa machine a des bases de données avec sqlite3 ou SQLAlchemy
-vertical-
Quelle base pour quel usage ?
SQLite est idéal pour les applications légères et le prototypage.
MySQL et PostgreSQL offrent des solutions de bases de données plus robustes et adaptées aux entreprises, avec des fonctionnalités étendues.
Microsoft SQL Server est privilégié dans les environnements où d’autres technologies Microsoft sont fortement utilisées.
-vertical-
Les bases de données NoSQL
NoSQL, ou « Not Only SQL », est un système de gestion de bases de données (SGBD) conçu pour gérer d’importants volumes de données non structurées et semi-structurées. Contrairement aux bases de données relationnelles traditionnelles qui utilisent des tables et des schémas prédéfinis, les bases de données NoSQL offrent des modèles de données flexibles et prennent en charge l’évolutivité horizontale, ce qui les rend idéales pour les applications modernes nécessitant un traitement de données en temps réel.
-vertical-
Pourquoi utiliser NoSQL ?
Contrairement aux bases de données relationnelles, qui utilisent le langage de requête structuré (SLR), les bases de données NoSQL ne disposent pas d’un langage de requête universel. Chaque type de base de données NoSQL possède généralement son propre langage de requête. Les bases de données relationnelles traditionnelles suivent les principes ACID (atomicité, cohérence, isolation, durabilité),garantissant une cohérence forte et des relations structurées entre les données.
-vertical-
Pourquoi utiliser NoSQL ?
Cependant, avec l’évolution des applications vers la gestion du Big Data, de l’analyse en temps réel et des environnements distribués, NoSQL s’est imposé comme une solution offrant :
- Évolutivité : possibilité d'évolutivité horizontale par l'ajout de nœuds au lieu de mettre à niveau une seule machine ;
- Flexibilité : prise en charge des données non structurées ou semi-structurées sans schéma rigide ;
- Hautes performances : optimisé pour des opérations de lecture/écriture rapides sur de grands ensembles de données ;
- Architecture distribuée : conçue pour une haute disponibilité et une tolérance aux partitions dans les systèmes distribués.
-vertical-
Types de bases de données NoSQL
Les bases de données NoSQL sont généralement classées en quatre catégories principales selon leur mode de stockage et de récupération des données.
- Bases de données documentaires
Les données sont stockées sous forme de documents pouvant contenir différents attributs (json, XML).
Exemples : MongoDB, CouchDB, Cloudant
Idéal pour les systèmes de gestion de contenu, les profils utilisateur et les catalogues nécessitant des schémas flexibles.
-vertical-
- Stockage clé-valeur
Les données sont stockées sous forme de paires clé-valeur, ce qui accélère considérablement la récupération. Optimisé pour la mise en cache et le stockage de sessions.
Exemples : Redis, Memcached, Amazon DynamoDB
Idéal pour les applications nécessitant la gestion des sessions, la mise en cache des données en temps réel et les classements.
-vertical-
- Stockage par famille de colonnes
Les données sont stockées en colonnes plutôt qu’en lignes, ce qui permet des analyses à grande vitesse et un calcul distribué. Efficace pour le traitement de données volumineuses avec des exigences élevées en écriture/lecture.
Exemples : Apache Cassandra, HBase, Google Bigtable
Idéal pour les données de séries chronologiques, les applications IoT et l’analyse du Big Data.
-vertical-
- Bases de données à base graphe
Les données sont stockées sous forme de nœuds et d’arêtes, ce qui permet une gestion complexe des relations. Idéal pour les réseaux sociaux, la détection des fraudes et les moteurs de recommandation.
Exemples : Neo4j, Amazon Neptune, ArangoDB
Utile pour les applications nécessitant des requêtes relationnelles, telles que la détection des fraudes et l’analyse des réseaux sociaux.
-vertical-
Avec python
Le framework le plus utilisé pour le NoSQL est MongoDB.
Un libairie pour se connecter à une base mongo existe en python :
c’est pymongo
PyMongo est la librairie officielle de MongoDB pour python
-vertical-
Les bases de données NoSQL sont idéales pour les données semi-structurées ou non structurées et s’adaptent efficacement aux flux à grande vitesse. Leur flexibilité et leur évolutivité en font la solution idéale pour les charges de travail dynamiques que les pipelines de ML doivent gérer.
-vertical-
Les deux types de bases de données peuvent être utilisés pour l’apprentissage automatique, selon le projet (à grande ou petite échelle). MySQL (base de données SQL) répond aux besoins des projets à petite échelle en offrant un nombre suffisant de fonctionnalités. MongoDB (base de données NoSQL) est préférable pour la production de projets et leur exploitation à grande échelle.
-vertical-
Depuis une API
Qu’est ce qu’une API ?
→ API veut dire Application Programming Interface
-vertical-
Qu’est ce qu’une API
Une API est un ensemble de protocoles et de sous-routines de communication utilisés par différents programmes pour communiquer entre eux. Un programmeur peut utiliser divers outils API pour simplifier son programme. De plus, une API offre aux programmeurs un moyen efficace de développer leurs logiciels. Ainsi, une API permet à deux programmes ou applications de communiquer entre eux en leur fournissant les outils et fonctions nécessaires. Elle reçoit la requête de l'utilisateur et l'envoie au fournisseur de services, puis renvoie le résultat généré par ce dernier à l'utilisateur souhaité.
-vertical-
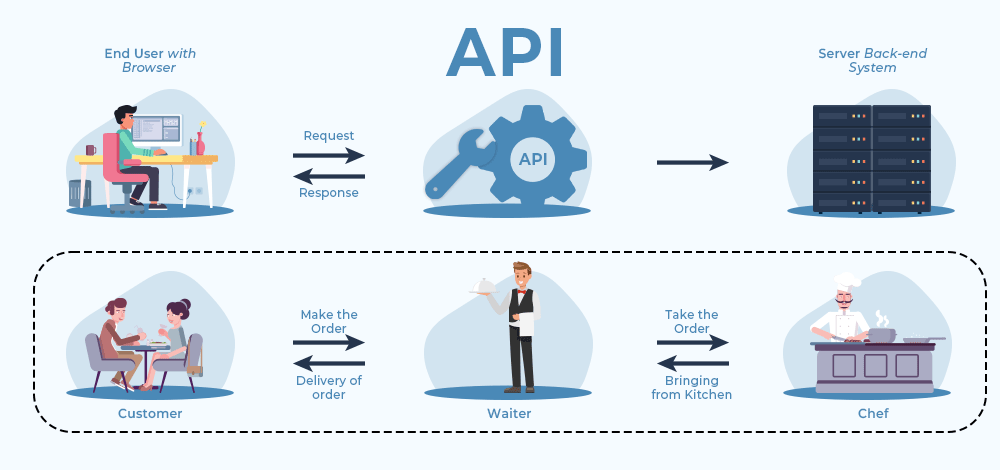
Comprendre par l’exemple
Pour illustrer le schéma d'une API, prenons un exemple concret. Imaginez un serveur de restaurant qui écoute votre commande, se rend chez le chef, prend les plats commandés et vous les remet.
exemple : vous recherchez une formation (par exemple, DSA-Self Paced) sur le site web XYZ. Vous envoyez une requête (recherche de produit) via une API. La base de données recherche la formation et vérifie sa disponibilité. L'API envoie votre requête à la base de données (recherche de la formation) et renvoie le résultat (meilleurs cours DSA).
-vertical-
Architecture
REST et GraphQL implémentent tous deux plusieurs principes architecturaux d’API communs. Par exemple, voici les principes qu’ils partagent :
Les deux étant apatrides, le serveur n’enregistre pas l’historique des réponses entre les requêtes Les deux utilisent un modèle client-serveur, de sorte que les demandes provenant d’un seul client aboutissent à des réponses provenant d’un seul serveur Les deux sont basés sur HTTP, car HTTP est le protocole de communication sous-jacent
-vertical-
Conception basée sur les ressources
REST et GraphQL conçoivent tous deux leur échange de données en fonction des ressources. Une ressource fait référence à toute donnée ou à tout objet auquel le client peut accéder et manipuler via l’API. Chaque ressource possède son propre identifiant unique (URI) et un ensemble d’opérations (méthodes HTTP) que le client peut effectuer sur elle.
-vertical-
Exemple
Prenons l’exemple d’une API de réseaux sociaux dans laquelle les utilisateurs créent et gèrent des publications. Dans une API basée sur les ressources, une publication serait une ressource. Elle possède son propre identifiant unique, par exemple /posts/1234. Et elle dispose d’un ensemble d’opérations, telles que GET pour récupérer la publication dans REST ou query pour récupérer la publication dans GraphQL.
-vertical-
Data Exchange
REST et GraphQL prennent tous deux en charge des formats de données similaires.
JSON est le format d'échange de données le plus populaire que tous les langages, plateformes et systèmes comprennent. Le serveur renvoie des données JSON au client. D'autres formats de données sont disponibles mais moins couramment utilisés, notamment XML et HTML.
De même, REST et GraphQL prennent tous deux en charge la mise en cache. Ainsi, les clients et les serveurs peuvent mettre en cache les données fréquemment consultées pour accélérer les communications.
-vertical-
Neutralité du langage et de la base de données
Les API GraphQL et REST fonctionnent avec n’importe quelle structure de base de données et n’importe quel langage de programmation, à la fois côté client et côté serveur. Cela les rend hautement interopérables avec n’importe quelle application.
-vertical-
Différences REST/GraphQL
le développement de REST s’est davantage concentré sur la création de nouvelles API. Dans le même temps, GraphQL s’est concentré sur les performances et la flexibilité des API.
-vertical-
Exemple
Voici ce qu’une requête REST utilise pour fonctionner :
- Verbes HTTP qui déterminent l’action
- Une URL qui identifie la ressource sur laquelle le verbe HTTP doit être activé
- Les paramètres et valeurs à analyser si vous souhaitez créer ou modifier un objet au sein d’une ressource côté serveur existante
Par exemple, vous utilisez GET pour obtenir des données en lecture seule à partir d'une ressource, POST pour ajouter une nouvelle entrée de ressource ou PUT pour mettre à jour une ressource.
-vertical-
Différences REST/GraphQL
En revanche, voici ce que les requêtes GraphQL utilisent :
- Requête pour obtenir des données en lecture seule
- Mutation pour modifier les données
- Abonnement pour recevoir des mises à jour de données basées sur des événements ou en streaming
-vertical-
Différences REST/GraphQL
Dans l’architecture REST, les données sont renvoyées au client par le serveur dans la structure complète des ressources spécifiée par le serveur. Les exemples suivants montrent les données renvoyées dans REST et GraphQL.
-vertical-
Exemple de données renvoyées dans REST Dans REST, GET /posts renvoie ce qui suit :
[
{
« id » : 1,
« titre » : « Premier message »,
« content » : « Ceci est le contenu du premier post. »
},
{
« id » : 2,
« titre » : « Deuxième message »,
« contenu » : « Ceci est le contenu du deuxième message »
},
{
« id » : 3,
« titre » : « Troisième message »,
« contenu » : « Ceci est le contenu du troisième message. »
}
]
-vertical-
Exemple de données renvoyées dans GraphQL Lorsque vous utilisez GraphQL, seules les données spécifiées dans la structure fournie par le client sont renvoyées.
GET /graphql?query{post(id: 1) {id title content}} renvoie uniquement le premier message :
{
« données » : {
"messages": [
{
« id » : « 1 »,
« titre » : « Premier message »,
« content » : « Ceci est le contenu du premier post. »
},
]}}
-vertical-
Quand utiliser GraphQL vs. REST
Vous pouvez utiliser les API GraphQL et REST de manière interchangeable. Cependant, dans certains cas d’utilisation, l’un ou l’autre convient mieux.
-vertical-
Par exemple, GraphQL est probablement un meilleur choix si vous tenez compte des points suivants :
- Vous avez une bande passante limitée et vous souhaitez minimiser le nombre de demandes et de réponses
- Vous disposez de plusieurs sources de données et vous souhaitez les combiner sur un seul point de terminaison
- Les demandes de vos clients varient considérablement et vous vous attendez à des réponses très différentes
-vertical-
Quand utiliser GraphQL vs. REST
D’un autre côté, REST est probablement un meilleur choix si vous tenez compte des considérations suivantes :
- Vous avez des applications plus petites avec des données moins complexes
- Vous disposez de données et d’opérations que tous les clients utilisent de la même manière
- Vous n’avez aucune exigence en matière de requêtes de données complexes
-vertical-
Et avec Python ?
Pour récupérer des données depuis le web (que ce soit API ou d’autres types de données), on utilise la bibliothèque
requests
La bibliothèque Requests est la norme de facto pour les requêtes HTTP en Python. Elle simplifie les requêtes grâce à
une API simple et élégante, vous permettant ainsi de vous concentrer sur l’interaction avec les services et la
consommation de données dans votre application.
-vertical-
Et avec Python ?
>>> import requests
>>> response = requests.get("https://api.github.com")
>>> response.content
Sur une API, on obtient un résultat en json qui est facile à parser
-vertical-
Gérer les réponses des APIs
Le python ne gère pas le format json de manière native.
Le format json se rapproche de la structure en dictionnaire de python
la bibliothèque json permet de traduire des données json vers un format dictionnaire exploitable en python.
Pour lire des chaînes de caractères json, on utilise la méthode :
json.loads()
-vertical-
Gérer les réponses des APIs
On peut aussi directement utiliser la bibliothèque pandas pour gérer les données renvoyée en json
import pandas as pd
pd.from_json()
-vertical-
Limite de débit
Comme pour toutes requêtes envoyées sur des serveurs, une limite de requête est décidée par les architectes des systèmes en fonction des specifications des machines.
les API limitent le nombre de requêtes d’API REST que vous pouvez présenter dans un laps de temps donné. Cette limite permet d’éviter la mauvaise utilisation et les attaques par déni de service, et garantit que l’API reste disponible pour tous les utilisateurs.
-vertical-
Les authentifications API
L’authentification API est le processus de vérification de l’identité d’un utilisateur effectuant une requête API. Il s’agit d’un pilier essentiel de la sécurité des API. Il existe de nombreux types d’authentification API, tels que l’authentification HTTP de base, l’authentification par clé API, JWT et OAuth, et chacun présente ses propres avantages, inconvénients et cas d’utilisation idéaux. Néanmoins, tous les mécanismes d’authentification API ont pour objectif commun de protéger les données sensibles et de garantir que l’API ne soit pas utilisée à mauvais escient.
-vertical-
Les méthodes d’authentification
L'authentification HTTP de base est la méthode la plus rudimentaire pour implémenter l'authentification API. Elle consiste à envoyer des identifiants sous forme de paires utilisateur/mot de passe dans un champ d'en-tête Authorization, où les identifiants sont codés en Base64. Cependant, ces identifiants ne sont ni hachés ni chiffrés, ce qui rend ce mécanisme d'authentification peu sûr, sauf s'il est utilisé conjointement avec HTTPS.

-vertical-
Les méthodes d’authentification
Une clé API est un identifiant unique qu'un fournisseur d'API attribue aux utilisateurs enregistrés afin de contrôler leur utilisation et de surveiller leur accès. La clé API doit être envoyée avec chaque requête, soit dans la chaîne de requête, soit comme en-tête de requête, soit comme cookie. Comme l'authentification HTTP de base, l'authentification par clé API doit être utilisée avec HTTPS pour garantir la sécurité de la clé API.

-vertical-
Les méthodes d’authentification
OAuth est un mécanisme d'authentification basé sur des jetons qui permet à un utilisateur d'accorder l'accès à son compte à des tiers sans avoir à partager ses identifiants de connexion. OAuth 2.0, plus flexible et évolutif qu'OAuth 1.0, est devenu la référence en matière d'authentification API et prend en charge une intégration API complète sans compromettre les données utilisateur.

-vertical-
Quiz 1
-
Quelle est la différence entre SQL et NoSQL ?
-
Donnez le nom d’un SGBD de NoSQL.
-
Que veut dire API ?
-horizontal-
Depuis le web
Le web scraping est une méthode automatique permettant d’extraire de grandes quantités de données de sites web. La plupart de ces données sont des données non structurées au format HTML, qui sont ensuite converties en données structurées dans un tableur ou une base de données afin d’être exploitées dans diverses applications. Il existe de nombreuses façons d’extraire des données de sites web grâce au web scraping.
-vertical-
Depuis le web
Parmi celles-ci, on peut citer l’utilisation de services en ligne, d’API spécifiques ou même la création de code web scraping de A à Z. De nombreux grands sites web, comme Google, Twitter, Facebook, StackOverflow, etc., disposent d’API permettant d’accéder à leurs données dans un format structuré. C’est la meilleure option, mais d’autres sites ne permettent pas d’accéder à de grandes quantités de données sous une forme structurée ou ne sont tout simplement pas assez avancés technologiquement. Dans ce cas, il est préférable d’utiliser le web scraping pour extraire les données du site web.
-vertical-
Crawler et Scrapper
Le web scraping se compose de deux éléments : le robot d’exploration (crawler) et le scraper. Le robot d’exploration est un algorithme qui parcourt le web à la recherche des données nécessaires en suivant les liens. Le scraper, quant à lui, est un outil spécifique conçu pour extraire les données du site web. La conception du scraper peut varier considérablement selon la complexité et l’ampleur du projet, afin de permettre une extraction rapide et précise des données.
-vertical-
Comment fonctionnent les crawlers ?
Internet est en constante évolution et expansion. Parce qu’il n’est pas possible de savoir combien de pages web existent au total sur Internet, les robots d’indexation commencent à partir d’une graine, c’est-à-dire une liste d’URL connues. Ils exploreront d’abord les pages web de ces URL. En indexant ces pages web, ils trouveront des hyperliens vers d’autres URL et les ajouteront à la liste des pages à indexer ensuite.
-vertical-
Exigences de robots.txt
les robots d’indexation décident également des pages à explorer en se basant sur le protocole robots.txt (également appelé protocole d’exclusion des robots). Avant d’indexer une page web, ils vérifient le fichier robots.txt hébergé par le serveur web de cette page. Un fichier robots.txt est un fichier texte qui définit les règles d’accès à l’application ou au site Web hébergé. Ces règles définissent les pages que les bots peuvent indexer et les liens qu’ils peuvent suivre. À titre d’exemple, consultez le fichier robots.txt de Cloudflare.com.
-vertical-
Comment fonctionnent les scrapers web ?
Les scrapers web peuvent extraire toutes les données de sites spécifiques ou les données spécifiques recherchées par un utilisateur. Idéalement, il est préférable de spécifier les données souhaitées afin que le scraper web les extraie rapidement. Par exemple, vous pourriez vouloir scraper une page Amazon pour connaître les types de centrifugeuses disponibles, mais vous pourriez ne vouloir que les données concernant les différents modèles, sans les avis clients.
-vertical-
Comment fonctionnent les scrapers web ?
Ainsi, lorsqu’un scraper web doit scraper un site, il commence par fournir les URL. Il charge ensuite tout le code HTML de ces sites. Un scraper plus avancé peut même extraire tous les éléments CSS et JavaScript. Le scraper récupère ensuite les données requises à partir de ce code HTML et les affiche au format spécifié par l’utilisateur. Il s’agit généralement d’une feuille de calcul Excel ou d’un fichier CSV, mais les données peuvent également être enregistrées dans d’autres formats, comme un fichier JSON.
-vertical-
Différence scraper-crawler
Les web scrapers peuvent se concentrer sur des pages ou sites web spécifiques uniquement, tandis que les robots d’indexation suivront les liens et les pages d’indexation en continu.
-vertical-
Web scraping en python
C'est le langage le plus populaire pour le web scraping, car il gère facilement la plupart des processus. Il propose également diverses bibliothèques spécialement conçues pour le web scraping. Scrapy est un framework d'exploration web open source très populaire, écrit en Python. Il est idéal pour le web scraping ainsi que pour l'extraction de données via des API. Beautiful soup est une autre bibliothèque Python particulièrement adaptée au web scraping. Elle crée un arbre d'analyse permettant d'extraire des données du code HTML d'un site web. Beautiful soup offre également de nombreuses fonctionnalités pour la navigation, la recherche et la modification de ces arbres d'analyse.
-vertical-
Attention à respecter le web!
Les sites donnent des informations sur la récupération de données qu’ils acceptent dans leurs robots.txt
on y retrouve :
- les agents qui sont autoriser à Scrapper
- la limite de débit
- …
-vertical-
🕯️Crawler le web🕯️
Aller récupérer le contenu des sites avec un crawler
Selenium
> from selenium import webdriver➡️ Une biliothèque pour automatiser les intéractions entre python et le navigateur
Requests
> import requests➡️ La bibliothèque de base pour requêter le web depuis Python
-vertical-
🕯️Scrapper le web🕯️
Récupérer le contenu textuel avec un scrapper
lxml
from lxml import etree➡️ La bibliothèque de base pour traiter du xml/html
Beautiful Soup
from bs4 import BeautifulSoup
➡️ Une bibliothèque très répendue pour faire à peu près pareil que lxml
- scrapy
import scrapy
-vertical-
Documents Semi-Structurés
Pour naviguer dans le contenu html, on utilise les concepts étudiés en cours de documents structurés et notamment XPATH
-vertical-
Comment on fait ?
→ Un exemple
💡f12 pour ouvrir l’inspecteur dynamique
💡ctrl+U pour ouvrir le code source de la page
-vertical-
Éviter le blocage IP : proxys et rotation des agents utilisateurs
Certains sites ne permettent pas de récupérer les informations contenue en leur sein.
Pourtant, en temps d'utilisateur, vous êtes autorisés à les consulter.
Comment est ce que les systèmes arrivent à déceler qui demande l'information ? → via l'adresse IP de l'utilisateur
Lorsqu'un utilisateur robot fait de nombreuses requêtes successive à un serveur, le serveur bloque cette adresse IP.
Evitez de faire des requêtes rapides à un serveur car vous serez vite bloqués.
-vertical-
🔭Qu'est ce qu'on récupère ?🔭
- Des images

- Des sons 🔊
- Des textes 🔡
-vertical-
Stocker les données pour le traitement
On veut stocker des données propres et facilement accessibles pour un traitement de machine learning.
La bibliothèque reine du traitement des données en python : pandas
-vertical-
Pandas
Pandas est compatible avec de nombreux format de données:
- xml
- json
- parquet
- csv
- …
-vertical-
huggingface Datasets
huggingface propose aussi sa propre bibliothèque de traitement de données : `datasets`
Elle est particulièrement utile pour récupérer des corpus pré-existant.
Dans ce cas, il n'est pas nécessaire de passer par les étapes vues précedemment car la libairie s'occupe d'elle même de préparer les données pour python
En revanche, il est important de comprendre commment la bibliothèque fonctionne pour créer votre propre corpus et le publier sur la plateforme.
Les données y sont souvent stockées en parquet
-vertical-
🖼️Convertir des images en texte🖼️
Les OCR
- Avec Python :
- py-tesseract
- doctr
- Avec les modèles multimodaux ? :
- GPT-4
- Gemini

-vertical-
🖼️Convertir des images en texte🖼️
Comment ça marche ❓

-vertical-
🔊Convertir les audio en texte🔊
Les modèles de speech-to-text
- Whisper
- Canary
-vertical-
🧼Convertir du texte en texte (propre)🧼
(Denoising Data)
- Comparer à un vocabulaire existant
- (distance d’édition : Levenshtein)
- Utiliser des modèles (avec les mask token pred.)
- Utiliser des LLM
-horizontal-
Le point bonne pratique
Suivre les conseils du MIT
L’importance de l’organisation des fichiers
La cohérence est essentielle. Comme pour se déplacer dans la maison, il est utile de savoir où se trouve chaque élément et de s'assurer qu'il est rangé dans un ordre logique (espérons que vos ustensiles de cuisine ne se trouvent pas dans votre salle de bain). Il en va de même pour le codage. Savoir où se trouvent les fichiers, quand utiliser tel code pour telle opération et comment trouver les résultats, données et chiffres associés peut non seulement optimiser la productivité, mais aussi favoriser la cohérence (même entre plusieurs projets) et le partage.
-vertical-
L’importance de l’organisation des fichiers
L’emplacement et l’organisation de vos fichiers peuvent être considérés comme une carte globale de vos projets de codage. Comme pour une légende de carte, vous devez définir un ensemble d’attentes concernant l’emplacement des différentes parties du projet et leur ordre d’assemblage.
-vertical-
Pourquoi le faire : pour les autres
Même si vous travaillez sur un devoir, il est préférable de garder à l'esprit que votre travail sera partagé et reproduit par d'autres. Pour cela, vous devez organiser votre code de manière à ce que les nouveaux arrivants puissent accéder rapidement aux éléments clés de votre projet sans consulter la documentation ni cliquer sans but dans les fichiers. D'une certaine manière, vous souhaitez que les autres vous remercient. Ils vous remercieront, espérons-le, pour :
- le temps gagné à apprendre la structure de votre projet ;
- la possibilité de collaborer plus facilement avec vous ;
- la compréhension rapide de la manière dont votre analyse a été réalisée ;
- la possibilité de reproduire rapidement votre code, ce qui renforce la confiance du collaborateur et la vôtre.
-vertical-
Pourquoi le faire : pour vous
Si vous avez déjà organisé votre bureau pour libérer de l'espace, tant physique que mental, vos projets de code méritent la même attention. Le temps investi pour apprendre à organiser votre code dès maintenant vous aidera à rationaliser vos projets futurs et à gagner en cohérence entre eux. Même si vous travaillez sur un devoir rapide, pensez aux centaines de devoirs similaires pour lesquels vous devez créer un dossier, puis bricoler quelques fichiers (nous vous déconseillons de tout mettre sur votre bureau). Ainsi, que vous travailliez sur des projets de petite ou de grande envergure, établir une structure standard renforcera la cohérence de votre travail et réduira le temps nécessaire à la rédaction de votre code standard.
-vertical-
Pourquoi le faire : pour le vous futur
-vertical-
Pourquoi le faire : pour le vous futur
Être confus n'est jamais agréable, surtout si vous en êtes la cause. Revenir au code et oublier où sont placés vos fichiers, ou pire, lesquels utiliser (la méthode tâtonnement fatale consistant à utiliser les suffixes fichier1.py, fichier-v1.py, fichier-mod1.py ou fichier-essayez-celui-ci-v1.py) est une expérience pénible. Pire encore, cela limite la capacité à reproduire votre code.
Par conséquent, établir une cohérence dès le départ – en commençant par une structure de fichiers et une convention de nommage standardisées – sera bénéfique pour votre futur. L'objectif est de remercier votre passé.
-vertical-
Exemple à suivre
PROJECT/
├── bin/ <- compiled binaries.
├── data/
│ ├── raw/
│ └── clean/
│
├── figures/ <- figures used in place of a "results"folder.
├── scripts/
│ ├── process/ <- scripts to maniuplate data between raw, cleaned final stages.
│ └── plot/ <- intermediate plotting.
│
├── src
│ ├── model1/ <- various experimental models.
│ ├── model2/
│ └── model3/
│
├── LICENSE
├── Makefile
└── readme.md
-vertical-
Exemple pour un projet python
PROJECT/
├── data/
│ ├── raw/
│ └── clean/
│
├── figures/ <- figures used in place of a "results"folder.
├── src/
│ ├── process/ <- scripts to maniuplate data between raw, cleaned final stages.
│ └── plot/ <- intermediate plotting.
│
├── bin
│ ├── model1/ <- various experimental models.
│ ├── model2/
│ └── model3/
│
├── LICENSE
├── Makefile
└── readme.md
-vertical-
Quiz 2
-
Dans un projet python, quel est le nom usuel du dossier dans lequel on mets les fichiers de scripts ?
-
A quoi doit-on faire attention pour ne pas outrepasser la limite de débit lorsque l’on scrappe un site web ?
-horizontal-
TP : Récuperer votre corpus de travail à partir d’une resource web
mettez votre script de crawling et de scraping sur votre github en respectant l’arborescence de dossiers présenté aujourd’hui.
- ⚠️Ne récupérez que des données qu'il est légal de récupérer
- ⚠️Vous n'avez pas à commit les fichiers récupérés dans votre repo → *push* des gros fichiers peut faire exploser votre git
- Votre code suffira pour l'évaluation
-vertical-
Quelques précisions sur l’évaluation
Le projet à rendre comprend:
- l’analyse d’un corpus pré-existant
- la constitution d’un corpus similaire à partir de données ouverte
- l’applications de visualisation sur ces données
- l’évaluation du corpus constitué