Outils de Traitement de Corpus
Cours d'Outils de traitement de Corpus - PluriTAL
Project maintained by EveSa Hosted on GitHub Pages — Theme by mattgraham
Outils de traitement de corpus
cours 3
-vertical-
Présentation de la newsletter
-horizontal-
Cours 4
Préparation des données - Part 1
-vertical-
Préparation des données : definition
→ transformation des données dans le but de les adapter au besoin de leur traitement
- reformatage
- correction
- combinaison
- enrichissement
-vertical-
Préparation des données : importance
→ contextualiser les données pour les transformer en informations pertinentes et d’éliminer les biais liés à une mauvaise qualité.
-vertical-
Préparation des données : importance
C’est une tâche très longue et fastidieuse de l’entraînement des modèles.
La préparation des données se découpe en plusieurs étapes:
- La récupération des données
- La compréhension et l’évaluation des données récupérées
- Le nettoyage et la validation
- La transformation et l’enrichissement
- Le stockage
-vertical-
Influence sur la qualité des modèles
la qualité du prétraitement a un impact direct sur les performances des modèles d’apprentissage automatique.
Un ensemble de données bien prétraité peut faire la différence entre un modèle qui peine à faire des prédictions précises et un modèle qui excelle dans ses tâches.
-vertical-
Influence sur la qualité des modèles
Les modèles ont besoin de voir un maximum de cas et de paramètres pour pouvoir généraliser.
ex. : un modèle de POS tagging doit avoir rencontré des adjectifs pour savoir prédire des adjectifs
-vertical-
2. Comprendre les données
Avant de réaliser quelconques transformations sur les données, il va falloir comprendre ce que l’on a récupéré.
examiner de plus près les données pour éviter les problèmes inattendus lors de la phase suivante, la préparation des données, qui est généralement la plus longue d’un projet.
-vertical-
La qualité d’un projet de Machine Learning dépend de la base de données sur laquelle il repose. Pour être performants, les modèles d’exploration de données de Machine Learning doivent intégrer de grandes quantités de données, et leur précision sera affectée si ces données ne sont pas explorées en profondeur au préalable.
-vertical-
Acceder aux données
L’organisation des données dans un format facilement utilisable pour la représentation et l’analyse est essentiel.
Je vous recommande d’utiliser un format lisible par pandas qui reste la bibliothèque phare pour l’analyse de donnée en python.
-vertical-
Décrire les données : Le Data Profiling
Quantité et Qualité
Combien de données a-t-on à notre disposition et dans quelles conditions elles ont été récupérées ?
-vertical-
Décrire les données : La quantité
- Quelle forme à notre corpus
- Quelle méthode on utilise pour le récupérer
- Combien de lignes, de colonnes à notre corpus ?
- Combien de classes différentes ?
-vertical-
Décrire les données : la qualité
- Est ce que les données sont bien en rapport avec notre tâche ?
- Quelles sont les types de données présentes ?
- Quelles statistiques peut on calculer pour ce corpus ?
- Quels sont les attributs majeurs ?
-vertical-
Explorer les données : Définition
L’exploration de données désigne l’étape initiale de l’analyse de données. Les analystes utilisent la visualisation et des techniques statistiques pour décrire les caractéristiques des ensembles de données, telles que leur taille, leur quantité et leur précision, afin de mieux comprendre leur nature.
-vertical-
Explorer les données : Définition
Les techniques d’exploration de données comprennent à la fois l’analyse manuelle et les solutions logicielles d’exploration automatisée qui explorent et identifient visuellement
- les relations entre les différentes variables
- la structure de l’ensemble de données
- la présence de valeurs aberrantes
- la distribution des valeurs afin de révéler des tendances et des points d’intérêt
-vertical-
Explorer les données : pourquoi ?
Les données sont souvent collectées en volumes importants et non structurés, provenant de sources diverses. Les analystes doivent d’abord comprendre et développer une vue d’ensemble des données avant d’en extraire les données pertinentes pour une analyse plus approfondie, telle qu’une analyse univariée, bivariée, multivariée et en composantes principales.
-vertical-
Explorer les données : Définition
Pour explorer les données, on va pouvoir réaliser des visualisations qui vont nous permettre de comprendre en un coup d’oeil comment s’organisent nos données.
Elles peuvent également contribuer à formuler des hypothèses et à structurer les tâches de transformation des données lors de la préparation des données.
-vertical-
Explorer les données
Détecter les erreurs dans les données.
ex. : Un bref résumé des dimensions des produits répertoriés permettra de détecter les fautes de frappe, comme « écran 119 pouces » (au lieu de « 19 pouces »).
-vertical-
Explorer les données
Détecter les erreurs dans les données.
ex. : Lorsqu’on récupère des articles de presse, certains sont libres de droits et d’autres sont tronqués après quelques lignes d’informations → visualiser la taille des textes et des résumés va nous permettre d’éliminer les élèments non pertinents.
-vertical-
La visualisation permet de :
- mieux appréhender les données et leur structure
- pouvoir faire des comparaisons avec d’autres données
- vulgariser/communiquer avec des non-experts
- résoudre un problème
- pouvoir acquérir de nouvelles connaissances
-vertical-
Le Quartet d’Anscombe
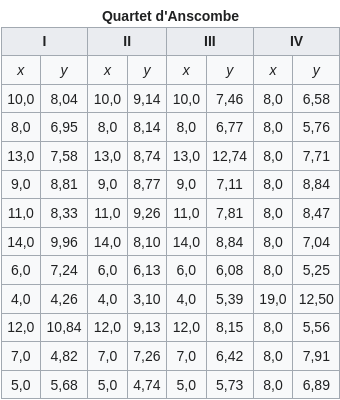
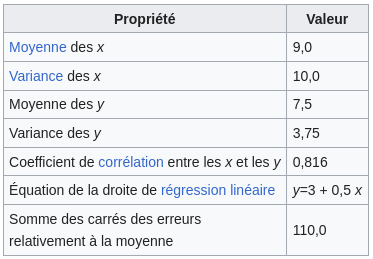

-vertical-
Les humains traitent mieux les données visuelles que les données numériques. Il est donc extrêmement difficile pour les data scientists et les analystes de donner du sens à des milliers de lignes et de colonnes de données et de communiquer ce sens sans aucun élément visuel.


-vertical-
On est bon pour reconnaitre les formes et les ordres de grandeurs

-vertical-
Pourquoi faire de la visualisation ?
- Faire de la visualisation =
Choisir une représentation pour résoudre un problème
Une représentation c’est :
- Des métriques (qu’est-ce que l’on veut représenter ?)
- Une échelle (comment voir le mieux les données ?)
- Une projection (comment choisir les variables de représentation ?)
-vertical-
Explorer les données
La visualisation des données dans l’exploration exploite des repères visuels familiers tels que
- les formes
- les dimensions
- les couleurs
- les lignes
- les points
- les angles
-vertical-
Explorer les données
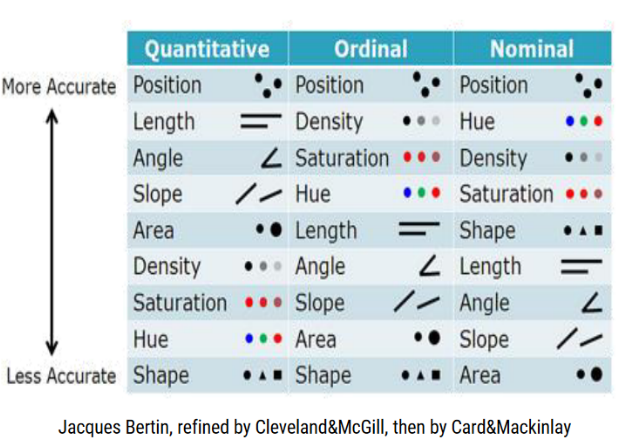
Ces caractéristiques permettent aux analystes de visualiser et de définir efficacement les métadonnées, puis de les nettoyer. La première étape de l’exploration des données permet aux analystes de mieux comprendre et d’identifier visuellement les anomalies et les relations qui pourraient autrement passer inaperçues.
-vertical-
Comment savoir quoi représenter ?
1. Identifier les variables
Définir chaque variable et son rôle dans l’ensemble de données.
-vertical-
Comment savoir quoi représenter ?
Analyse univariée :
- variables continues :
- créer des boîtes à moustaches
- des histogrammes pour chaque variable indépendamment
- variables catégorielles, :
- créer des graphiques à barres pour afficher les fréquences.
-vertical-
Comment savoir quoi représenter ?
Analyse bivariée : déterminer l’interaction entre les variables en créant des outils de visualisation.
- Continu et continu : nuages de points.
- Catégoriel et catégoriel : histogrammes empilés.
- Catégoriel et continu : boîtes à moustaches combinées à des swarmplots.
-vertical-
Feature Engineering
En plus de permettre de nettoyer le copus, l’exploration de données est de fournir des informations sur les données qui inspireront le feature ingeneering et le processus de construction du modèle.
Le feature engineering facilite le processus d’apprentissage automatique et augmente la puissance prédictive des algorithmes d’apprentissage automatique en créant des fonctionnalités à partir de données brutes.
-vertical-
L’exploration de données en Python
Exploration de données en Python L’exploration de données avec Python présente les avantages suivants :
- facilité d’apprentissage
- disponibilité opérationnelle
- intégration avec des outils courants
- bibliothèque complète et soutien d’une vaste communauté.
Presque tous les outils et fonctionnalités sont packagés et peuvent être exécutés par simple appel d’une méthode.
-vertical-
Bibliothèque pandas
pandas
- bibliothèque d’analyse de données
- Open Source
- fonctionne en Dataframe
- ouvre de nombreuses typologie de fichiers
-vertical-
Bibliothèque pandas
- Un objet dataframe performant pour la manipulation des données avec indexation intégrée
>>> import pandas as pd
>>> d = {'col1': [1, 2], 'col2': [3, 4]}
>>> df = pd.DataFrame(data=d)
>>> df
col1 col2
0 1 3
1 2 4
- Des outils de lecture et d’écriture de données entre différents formats
>>> pd.read_csv("file_path", delimiter = "\n")
>>> pd.read_json("file_path", lines=True)
-vertical-
Bibliothèque pandas
- Une gestion intégrée des données manquantes et un alignement intelligent des données
>>> df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
... "toy": [np.nan, 'Batmobile', 'Bullwhip'],
... "born": [pd.NaT, pd.Timestamp("1940-04-25"),
... pd.NaT]})
>>> df
name toy born
0 Alfred NaN NaT
1 Batman Batmobile 1940-04-25
2 Catwoman Bullwhip NaT
>>> df.dropna()
name toy born
1 Batman Batmobile 1940-04-25
-vertical-
Bibliothèque pandas
- Une flexibilité de pivotement et de remodelage des jeux de données
df.rename()
df.insert()
- Un découpage intelligent basé sur les étiquettes, une indexation sophistiquée et la création de sous-ensembles de grands jeux de données
>>> df.loc['viper']
max_speed 4
shield 5
Name: viper, dtype: int64
-vertical-
Bibliothèque pandas
- L’insertion et la suppression de colonnes dans les structures de données permettent de modifier la taille
>>> df = pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
>>> df
col1 col2
0 1 3
1 2 4
>>> df.insert(1, "newcol", [99, 99])
>>> df
col1 newcol col2
0 1 99 3
1 2 99 4
>>> df.insert(0, "col1", [100, 100], allow_duplicates=True)
>>> df
col1 col1 newcol col2
0 100 1 99 3
1 100 2 99 4
-vertical-
Bibliothèque pandas
- L’agrégation ou la transformation de données grâce à un puissant moteur de regroupement permettant des opérations de division, d’application et de combinaison sur les jeux de données
- Une fusion et une jointure hautes performances des jeux de données
- Une indexation hiérarchique des axes
Les techniques permettant d’améliorer l’exploration des données avec Pandas sont largement abordées sur les nombreux forums de la communauté Python.
-vertical-
Selectionner des caractéristiques
Pour choisir les bonnes caractéristiques à mettre en relation pour observer nos données, on peut utiliser la corrélation.
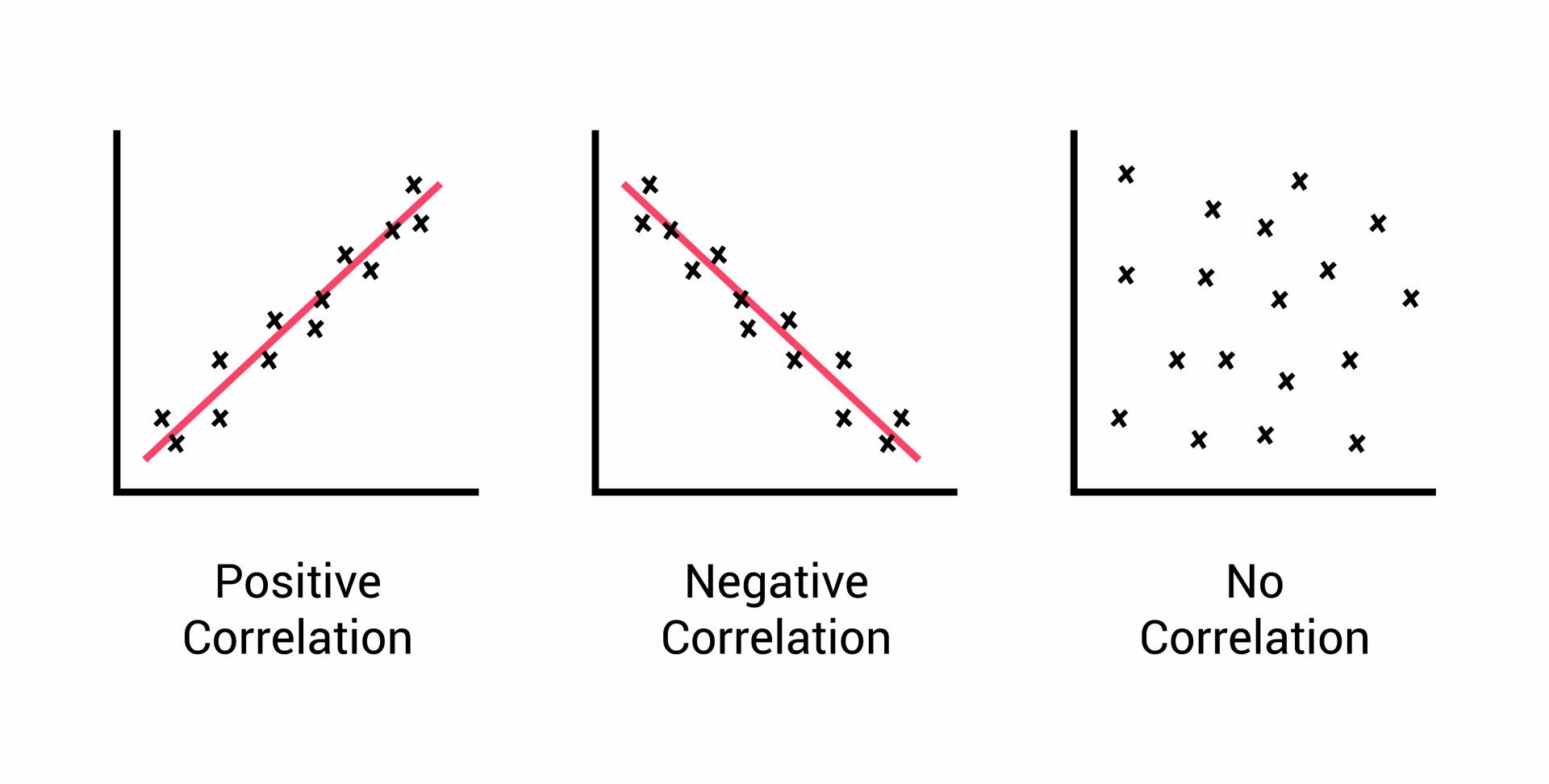
-vertical-
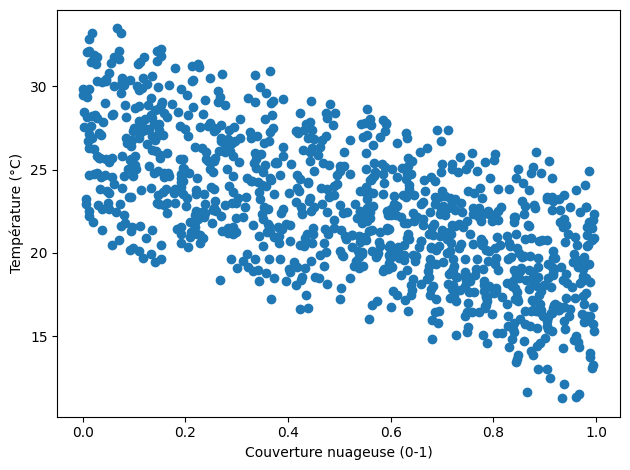
Est ce que la temperature est correlée à la couverture nuageuse?
→ pour le déterminer on va représenter les deux variables dans le même espace :
-vertical-
Ici, il n’est pas clair que les données corrèllent mais comment le vérifier ?
→ On va faire des tests de correlation
On décrit les corrélations à l'aide d'une mesure appelée coefficient de corrélation compris entre -1 et +1 et noté r.
-vertical-
Comme on observait précédemment,
On peut avoir une corrélation positive ou une corrélation négative :
-vertical-
- Si la corrélation est <0, elle est négative
→ On peut imaginer que plus la couverture nuageuse est forte, plus la température baisse
- Si la corrélation est >0, elle est positive
→ On peut imaginer que plus il fait jour longtemps, plus il fait chaud
-vertical-
Si la corrélation est proche de 0, on peut imaginer qu’il n’y a pas de corrélation entre les deux variables.
→ Mais comment déterminer s’il y a une corrélation significative ou pas ?
-vertical-
La significativité statistique est indiquée par une valeur p (“p-value”) comprise entre 0 et 1, du fait qu’il s’agit d’une probabilité. On dénote par alpha la valeur en dessous de laquelle il est admis qu’un résultat est significatif.
-vertical-
Dans de nombreux domaines, alpha = 0.05, mais divers seuils peuvent être présents :
- pour dénoter significatif (souvent alpha = 0.05)
- très significatif (souvent alpha = 0.01)
- extrêmement significatif (souvent alpha = 0.001), etc.
Dans des domaines spécifiques tels que l’astronomie, la significativité est exprimée sous la forme d’écart-types, du fait des distributions gaussiennes, auquel cas un résultat est considéré significatif à partir de 5 écart-types.
-vertical-
La p-value est impactée par la quantité de données : plus on a de données, plus le résultat d’ensemble est représentatif de la réalité de terrain.
Avec beaucoup de données, il est possible d’avoir des p-values très basses, considérez dans ce cas l’utilisation de la notation scientifique: 1.5e-10.
-vertical-
p-value
Dans un pile-ou-face, on souhaite savoir si la pièce est biaisée. Moyen: lancer la pièce un grand nombre de fois, et voir si une tendance émerge.
Exemple : lancer_la_piece(n=256, p=0.25)
Résultat : pile, face, pile, face, pile, pile, pile, face, pile, pile
-vertical-
Problème: même si la pièce n’est pas biaisée, la série qu’on observe reste possible.
Se pose alors la question : quelle est la probabilité d’observer une série au moins aussi extrême que celle observée (dans notre cas, s’écarter encore plus du 50/50). (cf. les cours de Damien Nouvel) Cela correspond à la p-value.
-vertical-
Quizz 1
-vertical-
Quizz 1
-
Pourquoi est ce que les modèles ont besoin de rencontrer des données variées ?
-
Quelle méthode pandas permet d’enlever les valeurs nulle d’un Dataframe ?
-
Que signifie une corrélation proche de 0 ?
-horizontal-
Transformer les données
- Nettoyer son corpus
-vertical-
🧼Nettoyer son corpus🧼
-vertical-
Dédupliquer les données
Il faut dédupliquer les données, pour ne pas biaiser l’apprentissage.
Un système qui apprend va approximer une vérité terrain à partir de ses données d’entrainement, qui ne sont qu’un faible échantillon de la vérité de terrain
→ par conséquent, toute surreprésentation d’un exemple du fait d’une duplication va biaiser le système en lui faisant croire que cet exemple est plus fréquent qu’il ne l’est vraiment.
-vertical-
(https://hplt-project.org/datasets/v1.2)[Corpus HPLT]
Comparez la version “raw” et la version “deduped”
22 TB of raw files → 11 TB of deduped files
-vertical-
Nettoyer les données
On a visualisé nos données avec les métriques adaptées à notre tâche
→ Les métriques mettent en lien des variables qui sont correlées
-vertical-
Rappel
Avec ces observations, on va également pouvoir observer si on a des items qui ne correspondent pas à ce que l’on voulait récupérer
par exemple : Lorsqu’on récupère des articles de presse, certains sont libres de droits et d’autres sont tronqués après quelques lignes d’informations → visualiser la taille des textes et des résumés va nous permettre d’éliminer les élèments non pertinents.
-vertical-
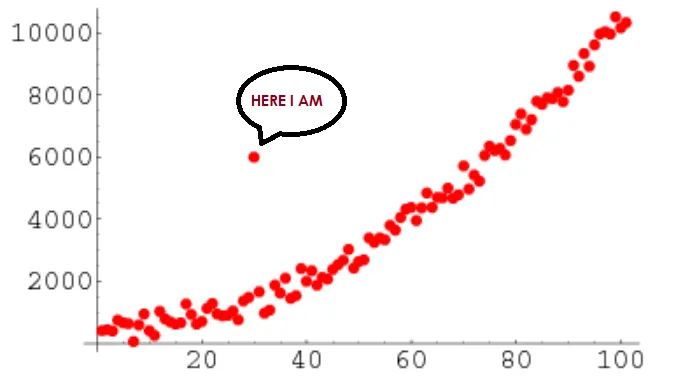
detecter les données aberrantes (outliers)
Qu’est ce qu’un outlier ?
-vertical-
Qu’est ce qu’un outlier ?
Une valeur aberrante est une valeur qui s’écarte fortement des valeurs des autres observations, anormalement faible ou élevée.
-vertical-
Il y a deux raison pour avoir ce genre de profil :
- Une erreur de mesure → Certains élèments de notre corpus ont été mal récupérés
- Une grande variabilité des données → les caratéristiques que l’on observe ne sont pas pertinentes pour juger de la qualité de nos données
-vertical-
Dans la distribution suivante, combien de valeurs abérrantes y a-t-il ?

-vertical-
Une valeur est considérée comme aberrante si la valeur absolue de l’écart avec Q1 ou Q3 est supérieure à plus de 1,5 x l’écart interquartile
Une valeur aberrante est dite:
-
faible si elle est inférieure à Q1 - 1,5 x l’écart interquartile
-
élevée si elle est supérieure à Q3 + 1,5 x l’écart interquartile
-vertical-
On peut aussi représenter ça sous forme de boîte

-vertical-
On veut enlever les données abérrantes de notre corpus pour conserver les caractéristiques voulues de notre modèle
→ Si on veut avoir un modèle de résumé automatique, on veut absolument enlever les paires texte-résumé qui ont un ratio de compression trop élevé
-vertical-
⚠ Attention toutefois à vérifier que vous n’enlevez pas trop de données avec cette méthode et que les données enlevées sont variées
→ Dans le cas d’une tâche de classification, si tous les outliers sont des items de la même classe, il va vous manquer des données pour cette classe.
-vertical-
On peut également couper la distribution pour éviter les valeurs trop éloignées

-vertical-
(https://hplt-project.org/datasets/v1.2)[Corpus HPLT]
Comparez la version “deduped” et la version “cleaned”
11 TB of deduped files → 8.6 TB of cleaned files
-vertical-
Le point bonne pratique
Faire du code de qualité :
“Code is read much more often than it is written.” Guido
-vertical-
Code de qualité
- Fonctionnalité
- Lisibilité
- Documentation
- Conformité aux normes
- Réutilisabilité
- Maintenabilité
- Robustesse
- Testabilité
- Efficacité
- Évolutivité
- Sécurité
-vertical-
Code de qualité
Toutes ces caractéristiques permettent aux développeurs de comprendre, modifier et étendre une base de code Python avec un minimum d’effort.
-vertical-
Fonctionnalité
Fonctionne comme prévu et remplit sa fonction prévue.
Lisibilité
Facile à comprendre. C’est à dire :
- avec des noms de variables clairs
-vertical-
Documenter
Explique clairement son objectif et son utilisation.
Commenter son code → les docstrings
“Code is read much more often than it is written.” Guido
-vertical-
- Les docstrings de module
Au début un fichier .py, on explique à quoi il sert et qu’est ce qu’il contient
"""Spreadsheet Column Printer
This script allows the user to print to the console all columns in the
spreadsheet. It is assumed that the first row of the spreadsheet is the
location of the columns.
This tool accepts comma separated value files (.csv) as well as excel
(.xls, .xlsx) files.
This script requires that `pandas` be installed within the Python
environment you are running this script in.
This file can also be imported as a module and contains the following
functions:
* get_spreadsheet_cols - returns the column headers of the file
* main - the main function of the script
"""
-vertical-
- Les docstrings de fonction ``` “"”Gets and prints the spreadsheet’s header columns
Parameters
file_loc : str The file location of the spreadsheet print_cols : bool, optional A flag used to print the columns to the console (default is False)
Returns
list a list of strings used that are the header columns “””
-vertical-
3. Les docstrings de Classe
””” A class used to represent an Animal
Attributes
says_str : str a formatted string to print out what the animal says … num_legs : int the number of legs the animal has (default 4)
Methods
says(sound=None) Prints the animals name and what sound it makes “””
-vertical-
#### Conformité aux normes
Respecte les conventions et directives, telles que PEP 8.
Outils:
linter comme `black`
-vertical-
#### Réutilisabilité
Peut être utilisé dans différents contextes sans modification.
→ d'où l'importance de coder en objet, de faire des petits scripts qui encodent une seule fonctionnalité, etc.
Comment utiliser son propre code comme une librairie ?
from src.mon_code import ma_fonction ```
-vertical-
Maintenabilité
Permet des modifications et des extensions sans introduire de bugs.
-vertical-
Robustesse
Gère efficacement les erreurs et les entrées inattendues.
Les utilisateurs sont vicieux. Il faut toujours prévoir comment ils vont pouvoir interférer avec le code.
Prévoir des vérifications de conditions et des raise error quand il y a besoin.
-vertical-
Testabilité:
L’exactitude peut être facilement vérifiée.
-vertical-
Efficacité
Optimise l'utilisation du temps et des ressources.
→ particulièrement important lors du traitement de données importantes !
tout traitement sur une ligne de votre dataframe devra être répétée sur autant de ligne que votre dataframe contient
Vous pouvez utiliser la fonction `%timeit` dans les notebook pour vous rendre compte du temps que prendra votre traitement.
il est toujours pertinent de faire une estimation du temps de traitement avant de le lancer
-vertical-
Évolutivité
Gère des charges de données accrues ou une complexité accrue sans dégradation.
Sécurité
Protège contre les vulnérabilités et les entrées malveillantes.
ex. : utiliser des protocoles de communications standardisés avec des méthodes d’authentifications sécurisées
-vertical-
Code de qualité
En résumé, un code de haute qualité est fonctionnel, lisible, maintenable et robuste. Il respecte les meilleures pratiques, notamment une dénomination claire, un style de codage cohérent, une conception modulaire, une gestion des erreurs appropriée et le respect des normes de codage. Il est également bien documenté et facile à tester et à faire évoluer. Enfin, un code de haute qualité est efficace et sécurisé, garantissant fiabilité et sécurité d’utilisation.
-vertical-
Quiz 2
-vertical-
Quiz 2
-
Ecrivez la docstring d’une fonction permettant de transformer un Dataframe pandas avec des valeurs manquantes en un Dictionnaire python plein.
-
Donnez une technique pour l’augmentation de données.
-horizontal-
TP
TP 3 - Visualiser les statistiques de corpus
-
Visualiser votre corpus à partir de statistiques de textes
ex. :
- longueur des textes
- mots fréquents (zipf)
- les statistiques adaptées à votre tâche
-
Utiliser une technique d’augmentation de données pour votre corpus
-vertical-
Augmentation de données et synthèse de données
Importance of Data Augmentation
Synthetic Data Generation Techniques
Oversampling (SMOTE)
Data Augmentation for Images & Text
Handling Small Datasets with Augmentation
Slides: 20
- Data Formatting and Transformation (30 min) Data Encoding (Categorical to Numerical)
Feature Scaling (Normalization vs. Standardization)
Data Type Conversions
Handling Imbalanced Data
Slides: 20
-vertical-
- Data Integration & Aggregation (30 min) (New Topic) Merging Multiple Data Sources
Data Joining & Concatenation
Aggregation for Time Series Data
Handling Conflicting Data Across Sources
Slides: 20
- Data Splitting and Partitioning (15 min) Train-Test-Split
Cross-Validation Techniques
Stratified Sampling
Slides: 10