Project maintained by EveSaHosted on GitHub Pages — Theme by mattgraham
Outils de Traitement de Corpus
-vertical-
Newsletter
-horizontal-
Cours 4:
Préparation des données
- partie 2
Augmentation les données
Segmenter les données pour l’apprentissage
-vertical-
1. Augmenter les données
Maintenant qu’on a récupéré et nettoyé notre corpus, on se retrouve peut être face à un problème de corpus déséquilibré.
Il nous manque des données dans une catégorie, on a trop de données dans une autre.
-vertical-
On parle de corpus déséquilibré lorsque :
Percentage of data belonging to minority class
Degree of imbalance
20-40% of the dataset
Mild
1-20% of the dataset
Moderate
<1% of the dataset
Extreme
-vertical-
1.A. Pourquoi on parle de données déséquilibrées ?
On peut ramener le déséquilibre des données à la notion d’Entropie
L’entropie (en théorie de l’information), est une mesure de l’incertitude.
Elle est essentielle en informatique et en particulier en Machine Learning.
-vertical-
Entropie de Shannon
Pour lever une incertitude (est ce qu’il va faire beau aujourd’hui), on va devoir récupérer une certaine quantité d’information.
On determine la probabilité d’un évènement par rapport au nombre de fois où l’évènement s’est produit:
→ le soleil s’est levé 100% des jours → la probabilité que le soleil se lève aujourd’hui est de 100%
-vertical-
Entropie de Shannon
Mais pour des cas où l’on est pas à 100% sûr, comment faire pour déterminer le niveau de certitude (où d’incertitude) ?
Si on essaie de savoir s’il va pleuvoir aujourd’hui et qu’on est dans un monde ou il pleut 50% des jours, on a juste besoin de poser la question “est ce qu’il pleut aujourd’hui ?” pour savoir la météo du jour.
On peut me répondre oui ou non et j’aurais la réponse à ma question
Pour 2 solutions possible, j’ai donc besoin d’une question avec une réponse binaire → 1 bit
-vertical-
Entropie de Shannon
Mais encore une fois c’est un cas un peu facile:
s’il a fait beau dans tous les jours que j’ai pu observer → j’ai besoin de 0 question (soit 0)
s’il a fait beau dans 50% des jours que j’ai pu observer → j’ai besoin de 1 question
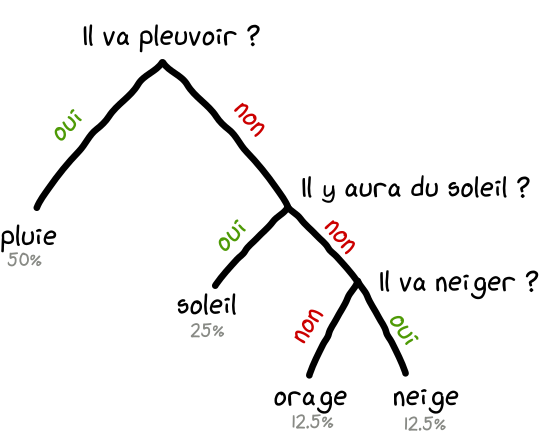
s’il a fait beau dans 25% des jours, qu’il a plu dans 50%, qu’il y a eu des nuages dans 12% et qu’il a neigé dans 12,5% → de combien de questions j’ai besoin ?
-vertical-
Entropie de Shannon
Comment faire pour limiter le nombre de questions dont j’ai besoin pour obtenir ma réponse ?
→ on va raisonner en arbre de probabilité
-vertical-
Entropie de Shannon
Dans 50% des cas, on a besoin de 1 question pour connaître la météo.
Dans 25% des cas, on a besoin de 2 questions pour connaître la météo.
Dans 12,5% des cas, on a besoin de 3 questions pour connaître la météo.
Dans 12,5% des cas, on a besoin de 3 quesitons pour connaître la météo.
Donc si on fait une moyenne :
$0.51\ bit\ +\ 0.252\ bit\ +\ 2(12.53\ bit)\ =\ 1.75\ bits$
→ c’est comme ça qu’on calcule l’entropie : c’est le nombre d’information dont on a besoin pour résoudre une incertitude
-vertical-
Entropie de Shannon
Pour l’écrire de manière plus concise, on veut faire la somme des probabilités multiplié par le nombre de questions nécessaires:
$sum(p_i * n_i)$
avec $p_i$ la probabilité de chaque évènement et $n_i$ le nombre de questions à poser pour obtenir cet évènement.
-vertical-
Entropie de Shannon
Comment est ce qu’on peut determiner le nombre de questions à poser pour une distribution d’évènement ?
Chaque question représente 2 solutions.
1 question = 2 solutions
2 questions = 4 solutions
3 questions = 8 solutions
x questions = $2^{x questions}$ solutions = nb de solutions
y solutions = $2^{x questions}$ solutions
-vertical-
Entropie de Shannon
Mais ce qu’on cherche ce n’est pas le nombre de solutions mais le nombre de questions qu’il faut poser !
Et le nombre de solution pour un nombre x de question dont on a besoin pour obtenir l’évènement e, c’est en fait l’inverse de la probabilité d’obtenir l’évènement e.
donc $nb solutions = log_2(1/p_i) = -log_2(p_i)$
-vertical-
Entropie de Shannon
Si on reprend notre calcul précédent
$0.51 bit + 0.252 bit + 2(0.1253 bit)$ = 1.75 bits
$=sum(p_i*n_i)$
Grâce à notre simplification précédente, on a besoin que
1.A. Pourquoi on parle de données déséquilibrées ?
Pourquoi ça nous intéresse pour la construction de nos jeux de données ?
Un jeu de donnée déséquilibré à une entropie faible. L’entropie est une bonne mesure pour l’équilibre de notre dataset.
L’entropie permet de déterminer combien d’information est contenu dans chaque exemple.
Mais revenons au problème : comme faire pour obtenir des données plus équilibrées ?
-vertical-
1.A. Pourquoi on ne diminue pas les classes majoritaire ?
L’idée la plus simple serait évidemment de diminuer la classe majoritaire pour la ramener à une quantité acceptable par rapport à la classe minoritaire. C’est ce qu’on appelle le downsampling.
Mais on sait que pour les modèles transformers, on a besoin de beaucoup de données. Diminuer notre classe majoritaire, ça veut dire risquer de se priver de données utiles pour notre entraînement.
On va donc plutôt vouloir augmenter les classes minoritaires quand on a pas beaucoup de données au départ ou si une diminution réduirait trop notre jeu d’entraînement.
-vertical-
1.b. Comment augmenter les classes minoritaires ?
Plusieurs Technique existent pour l’augmentation de données :
des méthodes par règles
des méthode par réseaux de neurones
-vertical-
1.b. Comment augmenter les classes minoritaires ?
Méthodes par règles
Le méthodes par règles peuvent utiliser de simple chercher-remplacer ou des techniques un peu plus complexes comme le remplacement par des synonymes (grâce à des bases comme WordNet)
-vertical-
##### 1.b. Comment augmenter les classes minoritaires ?
###### Méthodes par réseaux de neurones
Une des méthodes les plus utilisées est la retro-traduction (back-translation)
-vertical-
##### 1.b. Comment augmenter les classes minoritaires ?
###### Méthodes par réseaux de neurones
On peut également utiliser des techniques de remplacement de synonymes à l'aide de modèle de similarité.
Ces méthodes sont plus couteuses que des méthodes par exact matching mais permettent une plus grande variabilité.
-vertical-
##### 1.b. Comment augmenter les classes minoritaires ?
###### Les jeux de données synthétiques
Les données synthétiques sont des données artificielles conçues pour imiter les données du monde réel. Elles sont générées par des méthodes statistiques ou par des techniques d'intelligence artificielle (IA) telles que l'apprentissage profond et l'IA générative.
-vertical-
###### Jeux de données synthétiques
Bien que générées artificiellement, les données synthétiques conservent les propriétés statistiques sous-jacentes des données originales sur lesquelles elles reposent. Ainsi, les ensembles de données synthétiques peuvent compléter, voire remplacer, les ensembles de données réels.
-vertical-
**Quels intérêts aux jeux de données synthétiques ?**
Efficacité
Personnalisation
Données plus riches
-vertical-
**Quels intérêts aux jeux de données synthétiques ?**
*Confidentialité des données accrue*
Les données synthétiques ressemblent aux données réelles, mais peuvent être générées de manière à ce qu'aucune donnée personnelle ne puisse être reliée à une personne en particulier. Cela constitue une forme d'anonymisation des données, contribuant ainsi à la sécurité des informations sensibles. Les données synthétiques permettent également aux entreprises d'éviter les problèmes de propriété intellectuelle et de droits d'auteur, en éliminant les robots d'indexation qui collectent des informations sur les sites web à l'insu et sans le consentement des utilisateurs.
-vertical-
**Quels sont les côtés négatifs de la génération de jeux de données ?**
**Biais**
Les données synthétiques peuvent néanmoins présenter des biais, présents dans les données réelles sur lesquelles elles reposent. L'utilisation de sources de données diversifiées et l'ajout de multiples sources, notamment de régions et de groupes démographiques variés, peuvent contribuer à atténuer les biais.
-vertical-
**Effondrement du modèle**
L'effondrement du modèle se produit lorsqu'un modèle d'IA est entraîné de manière répétée sur des données générées par l'IA, ce qui entraîne une baisse de ses performances. Un mélange équilibré de données d'entraînement réelles et artificielles peut contribuer à prévenir ce problème.
-vertical-
##### 1.c. Transformer sont corpus
Ces méthodes permettent aussi de transformer son corpus. On peut décider de remplacer certains mots par des homophones, des antonymes, etc... pour obtenir des paires ou des ensembles de phrases que l'on va pouvoir comparer. Ca peut être utile pour observer l'efficacité des modèles sur la tâche de similarité par exemple.
-vertical-
#### 2. Segmenter les données pour l'apprentissage
Vous le savez déjà : Tout bon projet d'ingénierie logicielle consacre une énergie considérable aux tests de ses applications.
-vertical-
##### 2.a. Ensembles d'entraînement, de validation et de test
Vous devez tester un modèle sur un ensemble d'exemples différent de celui utilisé pour l'entraîner. Tester sur des exemples différents constitue une preuve plus solide de la pertinence du modèle que de tester sur le même ensemble d'exemples.
Où obtenir ces différents exemples ?
→ Traditionnellement, en apprentissage automatique, on les obtient en scindant l'ensemble de données d'origine. On peut donc supposer qu'il faut diviser l'ensemble de données d'origine en deux sous-ensembles
-vertical-
- Un ensemble d'entraînement sur lequel le modèle s'entraîne ;
- Un ensemble de test pour l'évaluation du modèle entraîné.
-vertical-
Diviser l'ensemble de données en deux est une bonne idée, mais une meilleure approche consiste à le diviser en trois sous-ensembles. Outre l'ensemble d'entraînement et l'ensemble de test, le troisième sous-ensemble est :
Un ensemble de validation qui permet d'effectuer les tests initiaux sur le modèle pendant son apprentissage.
-vertical-
Cette segmentation permet de mettre en place une suite de processus (workflow ou pipeline) efficace pour améliorer le modèle :
-vertical-
Mais même ici les ensembles de test et de validation s'usent avec les utilisations répétées. Autrement dit, plus vous utilisez les mêmes données pour prendre des décisions concernant les paramètres d'hyperparamètres ou d'autres améliorations du modèle, moins vous avez confiance dans la fiabilité des prédictions du modèle sur les nouvelles données. C'est pourquoi il est judicieux de collecter davantage de données pour actualiser les ensembles de test et de validation. Repartir de zéro est une excellente réinitialisation.
-vertical-
##### 2.b. Problèmes supplémentaires avec les ensembles de test
Les exemples en double peuvent affecter l'évaluation du modèle. Après avoir divisé un ensemble de données en ensembles d'entraînement, de validation et de test, supprimez tous les exemples de l'ensemble de validation ou de test qui sont des doublons d'exemples de l'ensemble d'entraînement. Le seul test fiable d'un modèle est celui des nouveaux exemples, et non des doublons.
-vertical-
Une précision trop importante de votre modèle sur les première itération peut être un signe d'une mauvaise gestion des données d'apprentissage et notamment de la contamination du modèle que vous venez d'entraîner
-vertical-
En résumé, un bon ensemble de test ou de validation répond à tous les critères suivants :
- Suffisamment grand pour produire des résultats de test statistiquement significatifs ;
- Représentatif de l'ensemble de données dans son ensemble. Autrement dit, ne choisissez pas un ensemble de test présentant des caractéristiques différentes de l'ensemble d'entraînement ;
- Représentatif des données réelles que le modèle rencontrera dans le cadre de ses activités ;
- Aucun exemple dupliqué dans l'ensemble d'entraînement.
-vertical-
-vertical-
Quizz 1
1. Calculez l'entropie de la distribution suivante : probabilité de l'évènement A (0,6) ; probabilité de l'évènement B (0,2) ; probabilité de l'évènement C (0,2)
2. Vous avez mélangé tous les exemples de l'ensemble de données et les avez divisés en ensembles d'entraînement, de validation et de test. Cependant, la valeur de _loss_ sur votre ensemble de test est si faible que vous suspectez une erreur. Qu'est-ce qui a pu se passer ?
-horizontal-
## Cours 4:
### Modèles d'apprentissage
-vertical-
### Rappel sur le ML
On sait qu'en Machine Learning, on a plusieurs manière d'obtenir unmodèle prédictif en fonction du type de notre tâche et de nos données:
- la regression
- la classification (ou regression logistique)
-vertical-
##### 1.A La regression linéaire
La régression linéaire est une technique statistique utilisée pour déterminer la relation entre des variables. Dans un contexte d'apprentissage automatique, elle permet de déterminer la relation entre des caractéristiques et une étiquette.
Cette relation nous permet de prédire des caratéristiques .
-vertical-
##### 1.A.i. La fonction de perte
La fonction de perte (ou _loss_) est une mesure numérique qui décrit le degré d'erreur des prédictions d'un modèle. Elle mesure l'écart entre les prédictions du modèle et les valeurs réelles. L'objectif de l'entraînement d'un modèle est de minimiser la perte, en la réduisant à sa valeur la plus faible possible.
-vertical-
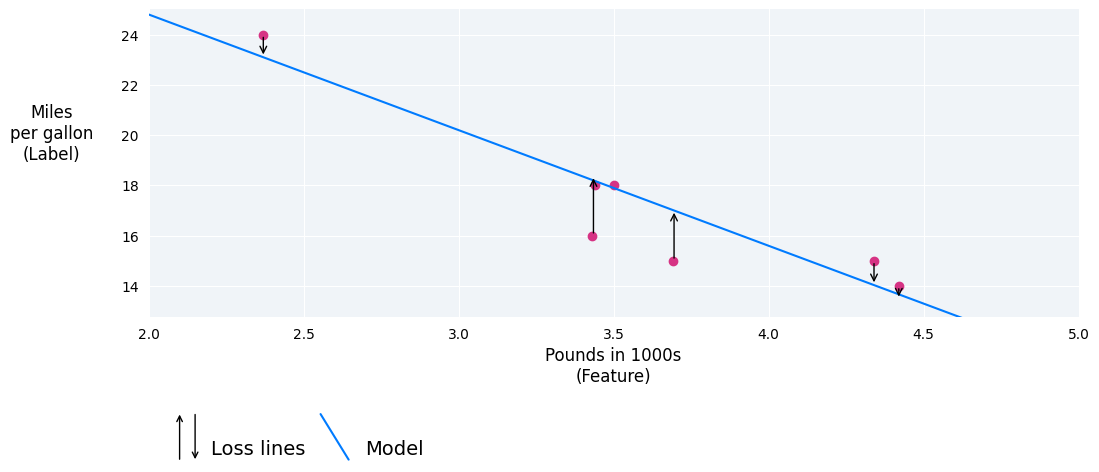
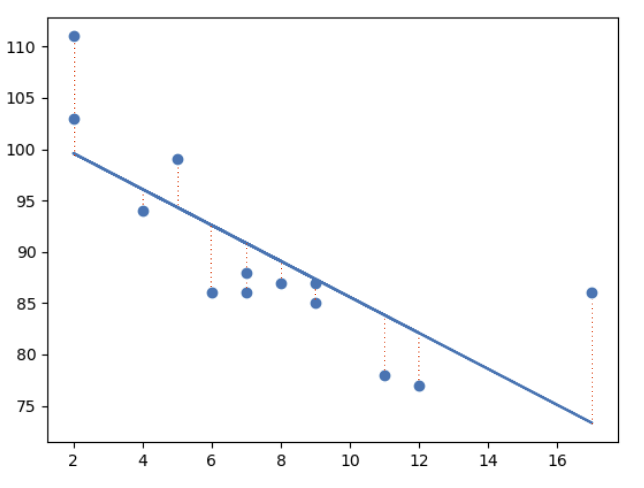
Dans l'image suivante, vous pouvez visualiser la perte sous forme de flèches reliant les points de données au modèle. Ces flèches indiquent l'écart entre les prédictions du modèle et les valeurs réelles.
-vertical-
Il y a plusieurs loss utilisées pour les problèmes de regression linéaire :
The average of L2 losses across a set of examples.
-vertical-
##### 1.A.ii. Choisir une perte
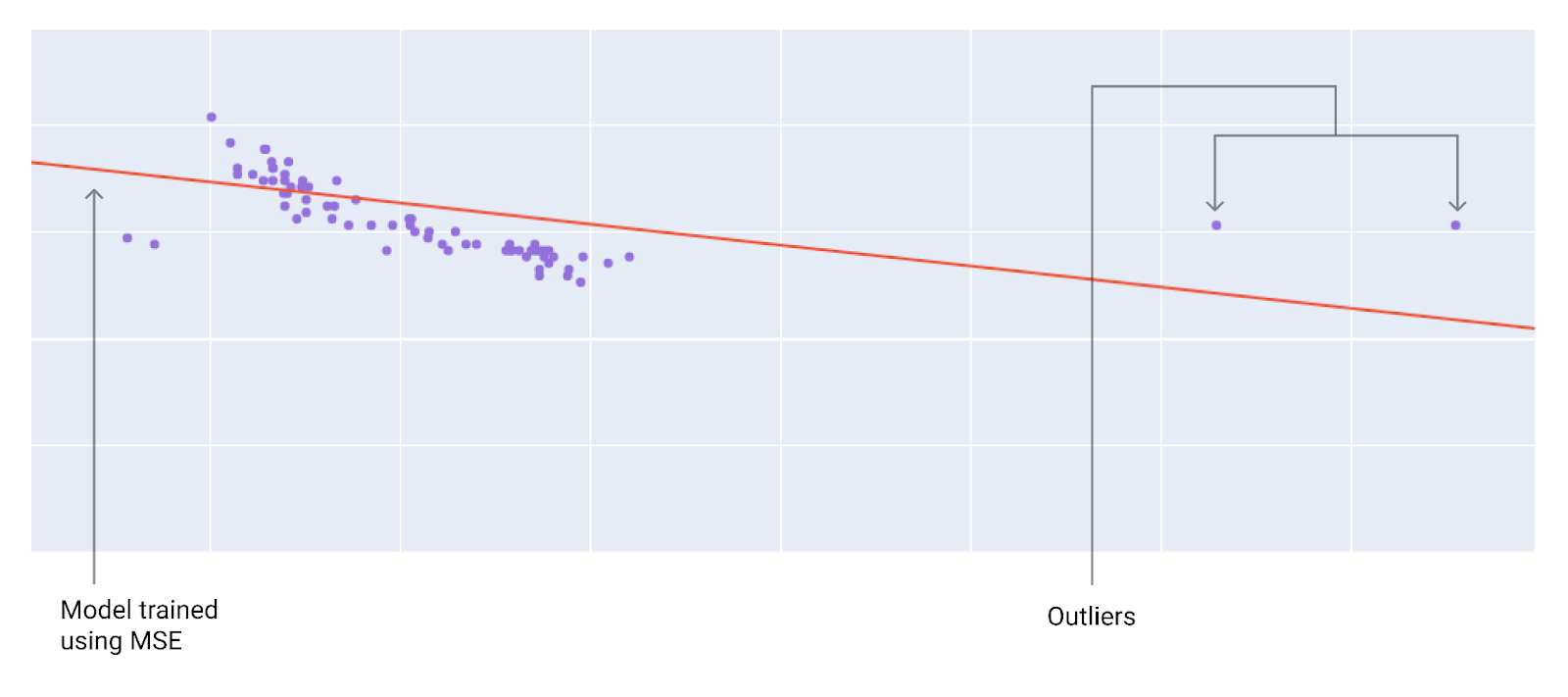
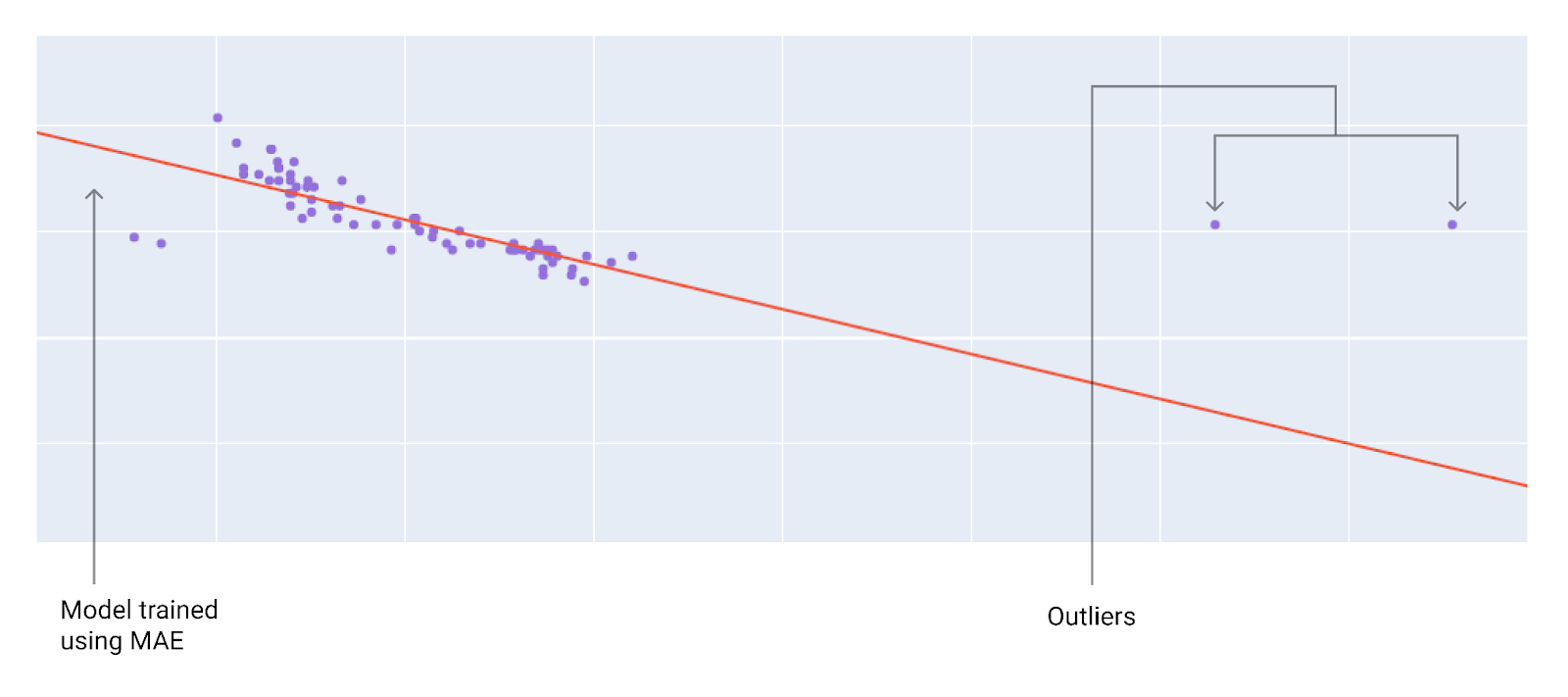
Le choix d'utiliser l'équation MAE ou MSE dépend du jeu de données et de la façon dont vous souhaitez traiter certaines prédictions. La plupart des valeurs des caractéristiques d'un jeu de données se situent généralement dans une plage distincte. Par exemple, les voitures pèsent généralement entre 900 et 2200 kg et consomment entre 13 et 80 km/l. Une voiture de 3600 kg, ou une voiture consommant 160 km/l, se situe en dehors de la plage habituelle et serait considérée comme une valeur aberrante.
-vertical-
Une valeur aberrante peut également indiquer l'écart entre les prédictions d'un modèle et les valeurs réelles. Par exemple, 1360 kg se situe dans la plage de poids typique d'une voiture, et 64 km/l se situe dans la plage de consommation de carburant typique. Cependant, une voiture de 1360 kg consommant 65 km/l serait une valeur aberrante selon les prévisions du modèle, car celui-ci prédirait qu'une voiture de 1360 kg consommerait entre 7 et 80 km/l.
Lors du choix de la meilleure fonction de perte, réfléchissez à la manière dont vous souhaitez que le modèle traite les valeurs aberrantes. Par exemple, la fonction MSE déplace le modèle vers les valeurs aberrantes, contrairement à la fonction MAE. La perte L2 entraîne une pénalité beaucoup plus élevée pour une valeur aberrante que pour une perte L1.
-vertical-
Par exemple, les images suivantes montrent un modèle entraîné avec la fonction MAE et un modèle entraîné avec la fonction MSE.
-vertical-
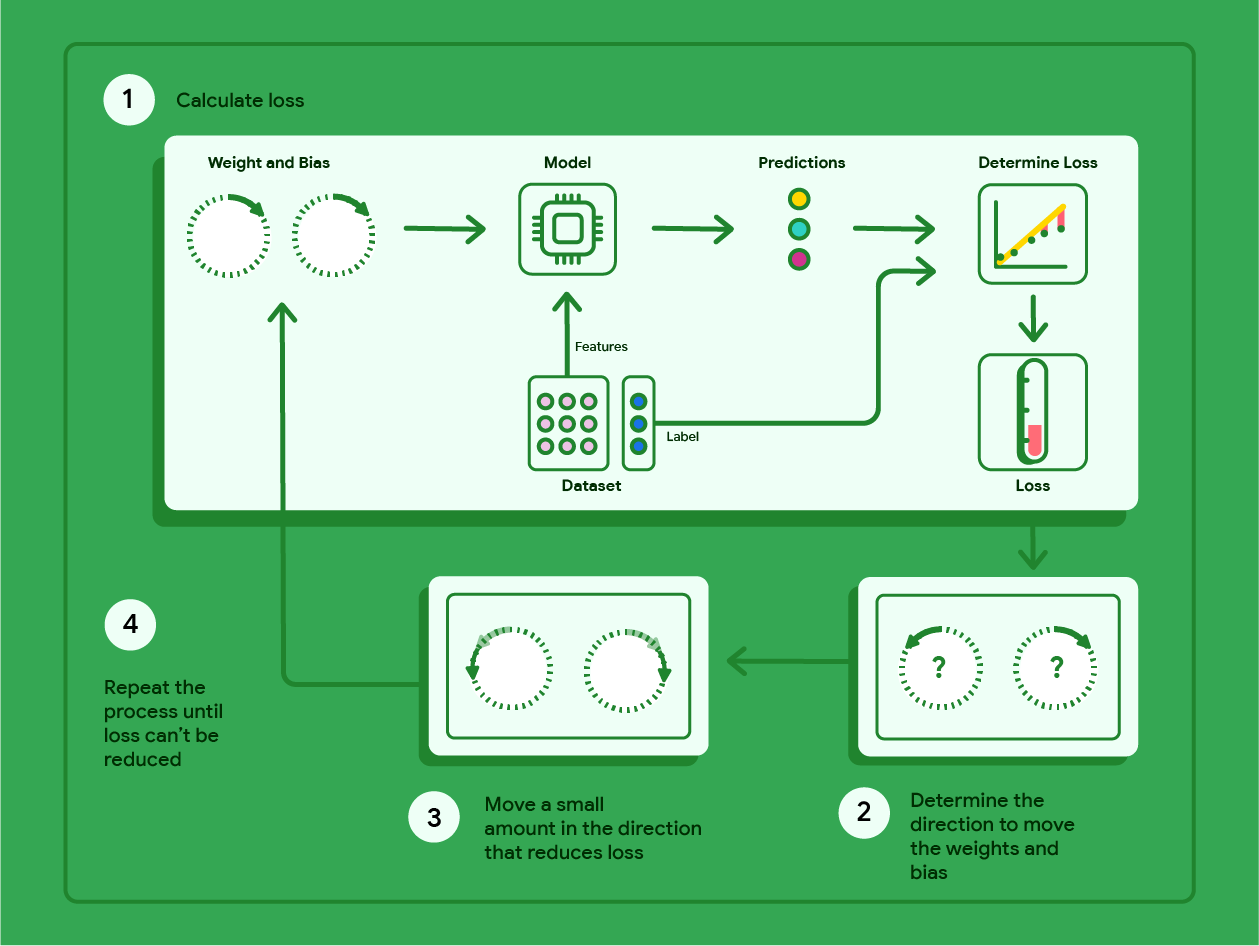
##### 1.A.iii. La descente de gradient
La descente de gradient est une technique mathématique qui permet de déterminer de manière itérative les pondérations et les biais permettant d'obtenir le modèle présentant la perte la plus faible. La descente de gradient permet de déterminer les pondérations et les biais les plus adaptés en répétant le processus suivant pour un nombre d'itérations défini par l'utilisateur.
-vertical-
Le modèle commence l'entraînement avec des pondérations et des biais aléatoires proches de zéro, puis répète les étapes suivantes :
1. Calculer la perte avec les pondérations et les biais actuels.
2. Déterminer la direction dans laquelle déplacer les pondérations et les biais pour réduire la perte.
3. Déplacer légèrement les valeurs de pondération et de biais dans la direction qui réduit la perte.
4. Revenir à l'étape 1 et répéter le processus jusqu'à ce que le modèle ne puisse plus réduire la perte.
-vertical-
-vertical-
###### 1.A.iv. La descente de gradient : un exemple
Concrètement, on peut parcourir les étapes de descente de gradient en utilisant un petit ensemble de données avec sept exemples de poids d'une voiture et de sa consommation d'essence :
Poids (feature)
L/km (label)
3.5
18
3.69
15
3.44
18
3.43
16
4.34
15
4.42
14
2.37
24
-vertical-
Le modèle commençe l'entraînement avec ses poids et ses biais à 0 :
`$$\small{Weight:\ 0}$$`
`$$\small{Bias:\ 0}$$`
`$\small{y = 0 + 0(x_1)}$`
On calcule la loss MSE avec les paramètres actuels :
$\small{Loss = \frac{(18-0)^2 + (15-0)^2 + (18-0)^2 + (16-0)^2 + (15-0)^2 + (14-0)^2 + (24-0)^2}{7}}$
$\small{Loss= 303.71}$
-vertical-
###### 1.A.iii.1. Les dérivées partielles
Pour obtenir la pente des lignes tangentes au poids et au biais, nous prenons la dérivée de la fonction de perte par rapport au poids et au biais, puis nous résolvons les équations.
L'équation d'une prédiction correpond à:
$f_{w,b}(x) = (w*x)+b$
On écrit la valeur réelle $y$
On calcule la MSE selon la formule suivante:
$\frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2$ où $M$ représente le nombre d'exemples.
-vertical-
###### 1.A.iii.2. Dérivative des poids
La dérivée de la fonction de perte par rapport au poids s'écrit :
$\frac{\partial }{\partial w} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2$
Qui correspond à:
$\frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2x_{(i)}$
-vertical-
###### 1.A.iii.2. Dérivative des poids
Nous additionnons d'abord chaque valeur prédite moins la valeur réelle, puis nous multiplions le résultat par deux fois la valeur de la caractéristique.
Ensuite, nous divisons la somme par le nombre d'exemples.
Le résultat est la pente de la droite tangente à la valeur du poids.
Si nous résolvons cette équation avec un poids et un biais égaux à zéro, nous obtenons **-119,7** pour la pente de la droite.
-vertical-
###### 1.A.iii.3. Dérivée du biais
La dérivée de la fonction de perte par rapport au biais s'écrit :
$\frac{\partial }{\partial b} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2$
et correspond à :
$\frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2$
-vertical-
###### 1.A.iii.3. Dérivée du biais
Nous additionnons d'abord chaque valeur prédite moins la valeur réelle, puis nous multiplions le résultat par deux. Nous divisons ensuite la somme par le nombre d'exemples. Le résultat est la pente de la droite tangente à la valeur du biais.
Si nous résolvons cette équation avec un poids et un biais égaux à zéro, nous obtenons **-34,3** pour la pente de la droite.
-vertical-
##### 1.A.iv. Learning rate et poids suivants
On déplace légèrement la valeur dans le sens de la pente négative pour obtenir la pondération et le biais suivants. Pour l'instant, nous définirons arbitrairement la « petite valeur » (le taux d'apprentissage ou _learning rate_) à 0,01 :
-vertical-
On utilise le nouveau poids et le nouveau biais pour calculer la perte, puis répétez l'opération. En effectuant le processus pendant six itérations, on obtient les poids, biais et pertes suivants:
Itération
Poids
Biais
Perte (MSE)
1
0
0
303,71
2
1.2
0,34
170.67
3
2,75
0.59
67,3
4
3.17
0.72
50,63
5
3,47
0.82
42.1
6
3,68
0,9
37,74
-vertical-
On remarque que la fonction de perte diminue à chaque mise à jour des poids et des biais. Ici, on s'arrête après six itérations. En pratique, un modèle est entraîné jusqu'à ce qu'il converge. Lorsqu'un modèle converge, les itérations supplémentaires ne réduisent pas davantage la perte, car la descente de gradient a trouvé les poids et les biais qui minimisent presque la perte.
-vertical-
##### 1.A.v. Convergence du modèle et courbes de perte
Lorsque vous entraînez un modèle, vous examinez souvent une courbe de perte pour déterminer si le modèle a convergé. La courbe de perte montre comment la perte change à mesure que le modèle s'entraîne. Voici à quoi ressemble une courbe de perte typique. La perte est représentée sur l'axe Y et les itérations sur l'axe X:
-vertical-
Vous pouvez constater que la perte diminue considérablement au cours des premières itérations, puis diminue progressivement avant de s'aplatir vers la 1 000e itération. Après 1 000 itérations, nous pouvons être presque certains que le modèle a convergé.
-vertical-
##### 1.A.vi. Paramètres et Hyperparamètres
Les paramètres d'un modèles (1B, 7B, ...), c'est en fait le nombres de poids et de biais du modèles. Ce sont toutes les parties "apprisent" par le modèle.
Ses Hyperparamètres, ce sont les parties choisies par le developpeur. On note quelques hyperparamètres importants:
- la taille de batch
- le taux d'apprentissage (learning rate)
- le nombre d'époques
-vertical-
**Taux d'apprentissage**
Le taux d'apprentissage influence la rapidité de convergence du modèle.
La différence entre les anciens paramètres du modèle et les nouveaux paramètres du modèle est proportionnelle à la pente de la fonction de perte. Par exemple, si la pente est importante, le modèle effectue un grand pas. Si elle est petite, il faut faire un petit pas. Par exemple, si l'ampleur de la pente est de 2,5 et que le taux d'apprentissage est de 0,01, le modèle modifie le paramètre de 0,025.
-vertical-
Le taux d'apprentissage idéal aide le modèle à converger en un nombre raisonnable d'itérations.
Si le taux d'apprentissage est trop faible, la convergence du modèle peut prendre beaucoup de temps. Toutefois, si le taux d'apprentissage est trop élevé, le modèle ne converge jamais, mais oscille autour des pondérations et des biais qui minimisent la perte. L'objectif est de choisir un taux d'apprentissage qui n'est ni trop élevé ni trop faible pour que le modèle converge rapidement.
-vertical-
Taux d'apprentissage trop faible :
-vertical-
Taux d'apprentissage trop élevé :
-vertical-
**Taille de batch (ou lot)**
La taille de lot est le nombre d'exemples que le modèle traite avant de mettre à jour ses poids et ses biais. Avec des jeux de données très grand, il n'est pas pratique d'utiliser tout le jeu de données avant de mettre à jour les poids : c'est trop couteux.
Deux techniques courantes pour obtenir le bon gradient en moyenne sans avoir à examiner chaque exemple de l'ensemble de données avant de mettre à jour les poids et le biais sont la descente aléatoire (stochastique) du gradient et la descente stochastique du gradient en mini-lot.
-vertical-
Avec une descente aléatoire (stochastique) du gradient, on ne choisi (aléatoirement) qu'un seul exemple du jeu de donnée avant de mettre à jour les poids du modèle.
Avec suffisamment d'itérations, l'utilisation d'un seul exemple fonctionne, mais n'est pas très efficient.
On peut observer que parfois la loss remonte.
-vertical-
Avec une descente de gradient stochastique par mini-lot, on choisi une taille de lot.
Pour un nombre de points de données N
, la taille de lot peut être n'importe quel nombre supérieur à 1 et inférieur à N
.Le modèle choisit les exemples inclus dans chaque lot de manière aléatoire (stochastique), calcule la moyenne de leurs gradients, puis met à jour les poids et le biais une fois par itération.
-vertical-
Le nombre d'exemples pour chaque lot dépend de l'ensemble de données et des ressources de calcul disponibles. En général, les petites tailles de lot se comportent comme la descente du gradient stochastique, tandis que les tailles de lot plus importantes se comportent comme la descente du gradient sur l'ensemble du lot.
-vertical-
**Époques (Epoch)**
Lors de l'entraînement, une époque signifie que le modèle a traité chaque exemple de l'ensemble d'entraînement une fois. Par exemple, étant donné un ensemble d'entraînement de 1 000 exemples et une taille de mini-lot de 100 exemples, le modèle nécessitera 10 itérations pour terminer une époque.
L'entraînement nécessite généralement de nombreuses époques. Autrement dit, le système doit traiter chaque exemple de l'ensemble d'entraînement plusieurs fois.
-vertical-
Le nombre d'époques est un hyperparamètre que vous définissez avant le début de l'entraînement du modèle. Dans de nombreux cas, vous devrez tester le nombre d'époques nécessaires pour que le modèle converge. En général, un nombre d'époques plus élevé produit un meilleur modèle, mais l'entraînement prend plus de temps.
-vertical-
#### 1.B. Regression Logistique
La regression linéaire est efficace pour prédire des valeurs. Avec certains types de données, on va plutôt vouloir calculer des probabilités qu'un element soit ou non d'un type, d'une classe.
Pour ça, il suffit de transformer les valeurs de la regression linéaire Pour la conditionner à donner des résultats entre 0 et 1.
-vertical-
La fonction qu'on utilise pour ça est la fonction suivante :
-vertical-
Pour faire la transformation, on a simplement à mettre la valeur de notre régression linéaire $z$ dans la formule de la fonction : $\frac{1}{1+e^{-x}}$
-vertical-
La regression logistique a ses propres fonctions de perte que l'on appelle log loss.
Pour faire de la classification, c'est la regression logistique que l'on transforme en prédictions binaires en choisissant un seuil de classification.
-vertical-
Quizz 2
-vertical-
Quizz 2
1. Quel modèle utiliser pour trouver les caractéristiques des données suivantes :
2. Calculez la descente de gradient du modèle $f(x)=wx=+b$ avec une Perte $L_2$ écrite $∑(valeur\ réelle - valeur\ prédite)^2$.
3. A quoi sert une taille de lot (batch) importante ?
-horizontal-
### Rappels sur le Deep Learning
Vous avez déjà vu que le problème de classification suivant est non linéaire :
-vertical-
« Non linéaire » signifie qu'il est impossible de prédire avec précision une étiquette avec un modèle de la forme $b+w_1*x_1 +w_2*x_2$
. Autrement dit, la surface de décision n'est pas une ligne.
Cependant, si nous effectuons un croisement de caractéristiques sur nos caractéristiques $x_1$
et $x_2$
, nous pouvons alors représenter la relation non linéaire entre les deux caractéristiques à l'aide d'un modèle linéaire : $b+w_1*x_1+w_2*x_2+w_3*x_3$
où $x_3$
est le croisement de caractéristiques entre
$x_1$ et $x_2$
:
-vertical-
Les réseaux de neurones sont efficaces pour calculer ces croisements de caractéristiques .
Les réseaux de neurones constituent une famille d'architectures de modèles conçues pour trouver les non-linéarité des modèles dans les données.
-vertical-
#### 1. Noeuds et Couches cachées
Les noeuds sont les différents $x_n$ de notre regression linéaire.
Sur un réseau à 1 couche, avec une fonction d'activation linéaire, il n'y a pas de différence avec une régression linéaire classique.
On a la même formule $y=w_1*x_1+w_2*x_2$
-vertical-
Pour quitter la linéarité, on va vouloir ajouter des modifications des résultats au milieu de notre calcul.
On va ajouter une couche "cachées" constituées de "neurones" entre les entrées et le résultat
-vertical-
Sans modifier plus que ça notre réseau, on ne peut pas calculer de non-linéarité parceque le résultat final correpond toujours à la somme de $(x_1w_1+b_1)w_2+b_2=(w_2*w_1)*x_1+w_2b_1+b_2$
On va vouloir casser la linéarité en applicant des fonctions non linéaire à la sortie de chaque couche.
On a déjà vu une fonction non linéaire pour la régression logistique : la fonction sigmoïde.
-vertical-
Maintenant que nous avons ajouté une fonction d'activation, l'ajout de couches a plus d'impact. L'empilement de non-linéarités nous permet de modéliser des relations très complexes entre les entrées et les sorties prévues. En résumé, chaque couche apprend une fonction plus complexe et de niveau supérieur par rapport aux entrées brutes.
-vertical-
**Fonction d'activation**
On appelle la fonction qu'on met en sortie du neurone la fonction d'activation. On peut utiliser plusieurs types de fonctions différentes : les sigmoïde, les ReLU, ...
-vertical-
Sauf que maintenant qu'on a plus de linéarité, comment est ce qu'on va pouvoir calculer le gradient de notre fonction ?
→ on va utiliser la retropropagation
La logique de la rétropropagation repose sur le fait que les couches de neurones des réseaux neuronaux artificiels sont essentiellement une série de fonctions mathématiques imbriquées. Lors de l'apprentissage, ces équations interconnectées sont imbriquées dans une autre fonction : une « fonction de perte » qui mesure la différence (ou « perte ») entre la sortie souhaitée (ou « vérité fondamentale ») pour une entrée donnée et la sortie réelle du réseau neuronal.
Nous pouvons donc utiliser la « règle de la chaîne » pour calculer la contribution de chaque neurone à la perte globale. Ce faisant, nous pouvons calculer l'impact des modifications de n'importe quelle variable – c'est-à-dire de n'importe quel poids ou biais – dans les équations représentées par ces neurones.
-vertical-
La règle de la chaîne est une formule permettant de calculer les dérivées de fonctions impliquant non seulement plusieurs variables, mais plusieurs fonctions. Prenons par exemple une fonction composée $f(x) = A(B(x))$. La dérivée de la fonction composée, f, est égale à la dérivée de la fonction externe (A) multipliée par la dérivée de la fonction interne (B).
-vertical-
D'un point de vue technique et mathématique, l'objectif de la rétropropagation est de calculer le gradient de la fonction de perte par rapport à chacun des paramètres individuels du réseau neuronal. En termes plus simples, la rétropropagation utilise la règle de la chaîne pour calculer le taux de variation de la perte en réponse à toute modification d'un poids (ou biais) spécifique du réseau.
On va calculer les dérivées couches par couches et on pourra ensuite donner les dérivées que l'on a calculées à la couche précédente pour qu'elle l'utilise pour calculer sa propre dérivée.
-vertical-
Pour 4 couches A, B, C, D, on a $y=A(B(C(D(x))))$ → on va commencer par calculer $D(x)'$ Puis on va utiliser $D(x)'$ pour calculer $C(D(x))' = C(x)'*D(x)'$ etc.
A la fin de la retro-propagation, on obtient le gradient de la fonction de perte globale.
-vertical-
Avec le gradient, on peut faire, comme pour la regression linéaire, la descente de gradient qui nous permet de modifier la valeurs des poids des différents neurones.
-vertical-
**Le problème du *Vanishing gradiant***
Les gradients des couches de réseau neuronal inférieures (celles qui sont plus proches de la couche d'entrée) peuvent devenir très petits. Dans les réseaux profonds (réseaux avec plusieurs couches cachées), le calcul de ces gradients peut impliquer de prendre le produit de nombreux petits termes.
Lorsque les valeurs du gradient s'approchent de 0 pour les couches inférieures, les gradients "disparaissent". Les couches avec des gradients qui disparaissent s'entraînent très lentement, voire pas du tout.
-vertical-
Certaines fonctions d'activation (genre ReLU) permettent de limiter la disparition du gradient.
-vertical-
**Gradients explosifs**
Si les pondérations d'un réseau sont très importantes, les gradients des couches inférieures impliquent le produit de nombreux termes de grande taille. Dans ce cas, vous pouvez avoir des gradients explosifs: des gradients qui deviennent trop importants pour converger.
La normalisation des lots peut aider à éviter l'explosion des gradients, tout comme la réduction du taux d'apprentissage.
-vertical-
Quiz 3
-vertical-
1. Vrai ou faux: la réduction du taux d'apprentissage peut aider à éviter l'explosion des gradients pendant l'entraînement des réseaux de neurones.
2. Pourquoi est-ce que le réseau de neurone suivant est il linéaire sans activation ? couche d'entrée: $w_1*x+w_2*x+b_1$ et couche cachée :$w_3*x+b$. Dessinez le réseau et écrivez sont équation.
3. Qu'est ce que la retropropagation (back propagation) ?
-vertical-
### 3. Les transformers
#### 3.A. Architecture
Le modèle est principalement composé de deux blocs :
Encodeur : L’encodeur reçoit une entrée et en construit une représentation (ses caractéristiques). Cela signifie que le modèle est optimisé pour comprendre l’entrée.
Décodeur : Le décodeur utilise la représentation de l’encodeur (caractéristiques) ainsi que d’autres entrées pour générer une séquence cible. Cela signifie que le modèle est optimisé pour générer des sorties.
-vertical-
Chacune de ces parties peut être utilisée indépendamment, selon la tâche :
Modèles encodeur seul : Convient aux tâches nécessitant une compréhension de l'entrée, comme la classification de phrases et la reconnaissance d'entités nommées.
Modèles décodeur seul : Convient aux tâches génératives comme la génération de texte.
Modèles encodeur-décodeur ou modèles séquence à séquence : Convient aux tâches génératives nécessitant une entrée, comme la traduction ou le résumé.
-vertical-
**Couches d'attention**
Une caractéristique clé des modèles Transformer est qu'ils sont construits avec des couches spéciales appelées couches d'attention. D'ailleurs, le titre de l'article présentant l'architecture Transformer était « Attention Is All You Need » ! Cette couche indique au modèle d'accorder une attention particulière à certains mots de la phrase que vous lui avez transmise (et d'ignorer plus ou moins les autres) lors du traitement de la représentation de chaque mot.
-vertical-
Pour mettre cela en contexte, prenons l'exemple de la traduction d'un texte de l'anglais vers le français. Avec l'entrée « Vous aimez ce cours », un modèle de traduction devra également tenir compte du mot adjacent « Vous » pour obtenir la traduction correcte du mot « aimer », car en français, le verbe « aimer » se conjugue différemment selon le sujet. Le reste de la phrase, en revanche, n'est pas utile pour la traduction de ce mot. De même, pour traduire « ceci », le modèle devra également prêter attention au mot « cours », car « ceci » se traduit différemment selon que le nom associé est masculin ou féminin. Là encore, les autres mots de la phrase n'auront aucune importance pour la traduction de « cours ». Dans des phrases plus complexes (et des règles grammaticales plus complexes), le modèle devra prêter une attention particulière aux mots qui pourraient apparaître plus loin dans la phrase afin de traduire correctement chaque mot.
-vertical-
**L'architecture originale**
L'architecture Transformer a été conçue à l'origine pour la traduction.
Lors de l'apprentissage, l'encodeur reçoit des entrées (phrases) dans une langue donnée, tandis que le décodeur reçoit les mêmes phrases dans la langue cible souhaitée.
-vertical-
Dans l'encodeur, les couches d'attention peuvent utiliser tous les mots d'une phrase (car, comme nous venons de le voir, la traduction d'un mot donné peut dépendre de ce qui le précède ou le suit dans la phrase).
Le décodeur, quant à lui, fonctionne séquentiellement et ne peut prêter attention qu'aux mots de la phrase qu'il a déjà traduits (donc uniquement aux mots précédant le mot en cours de génération).
-vertical-
Par exemple, lorsque nous avons prédit les trois premiers mots de la cible traduite, nous les transmettons au décodeur, qui utilise ensuite toutes les entrées de l'encodeur pour tenter de prédire le quatrième mot.
-vertical-
Pour accélérer l'apprentissage (lorsque le modèle a accès aux phrases cibles), le décodeur reçoit la cible complète, mais n'est pas autorisé à utiliser les mots futurs (s'il avait accès au mot en position 2 lors de la prédiction du mot en position 2, le problème ne serait pas très compliqué). Par exemple, lors de la prédiction du quatrième mot, la couche attentionnelle n'aura accès qu'aux mots des positions 1 à 3.
-vertical-
The original Transformer architecture looked like this, with the encoder on the left and the decoder on the right:
-vertical-
Notez que la première couche d'attention d'un bloc décodeur prend en compte toutes les entrées (passées) du décodeur, tandis que la seconde couche utilise la sortie de l'encodeur. Elle peut ainsi accéder à l'intégralité de la phrase d'entrée pour prédire au mieux le mot courant. Ceci est très utile car différentes langues peuvent avoir des règles grammaticales qui placent les mots dans des ordres différents, ou un contexte fourni plus loin dans la phrase peut aider à déterminer la meilleure traduction d'un mot donné.
-vertical-
Le masque d'attention peut également être utilisé dans l'encodeur/décodeur pour empêcher le modèle de prêter attention à certains mots spéciaux, par exemple le mot de remplissage spécial utilisé pour rendre toutes les entrées de la même longueur lors du regroupement de phrases.
-vertical-
**Architectures vs. points de contrôle (checkpoints)**
Architecture : Il s'agit du squelette du modèle, c'est-à-dire la définition de chaque couche et de chaque opération qui s'y déroule.
Points de contrôle : Il s'agit des pondérations qui seront chargées dans une architecture donnée.
Modèle : Il s'agit d'un terme générique, moins précis que « architecture » ou « point de contrôle », car il peut désigner les deux.
Par exemple, BERT est une architecture, tandis que bert-base-cased, un ensemble de pondérations entraînées par l'équipe Google pour la première version de BERT, est un point de contrôle. Cependant, on peut parler de « modèle BERT » et de « modèle bert-base-cased ».
-vertical-
##### Modèles encodeurs
Les modèles d'encodeur utilisent uniquement l'encodeur d'un modèle Transformer. À chaque étape, les couches d'attention peuvent accéder à tous les mots de la phrase initiale. Ces modèles sont souvent caractérisés comme ayant une attention « bidirectionnelle » et sont souvent appelés modèles d'auto-encodage.
-vertical-
Le pré-entraînement de ces modèles consiste généralement à corrompre une phrase donnée (par exemple, en masquant des mots aléatoires) et à charger le modèle de retrouver ou de reconstruire la phrase initiale.
Les modèles d'encodeur sont particulièrement adaptés aux tâches nécessitant la compréhension de la phrase complète, telles que la classification de phrases, la reconnaissance d'entités nommées (et plus généralement la classification de mots) et la réponse à des questions par extraction.
-vertical-
##### Modèles décodeurs
Les modèles de décodeur utilisent uniquement le décodeur d'un modèle Transformer. À chaque étape, pour un mot donné, les couches d'attention ne peuvent accéder qu'aux mots qui le précèdent dans la phrase. Ces modèles sont souvent appelés modèles autorégressifs.
Le pré-apprentissage des modèles de décodeur repose généralement sur la prédiction du mot suivant dans la phrase.
Ces modèles sont particulièrement adaptés aux tâches impliquant la génération de texte.
-vertical-
**Grands modèles de langues (LLM) modernes**
La plupart des LLM modernes utilisent une architecture à décodeur seul. Ces modèles ont connu une croissance spectaculaire en taille et en capacités ces dernières années, certains des plus grands modèles contenant des centaines de milliards de paramètres.
L'entraînement des LLM modernes se déroule généralement en deux phases :
- Pré-entraînement : le modèle apprend à prédire le prochain jeton sur de grandes quantités de données textuelles
- Optimisation des instructions : le modèle est affiné pour suivre les instructions et générer des réponses utiles
-vertical-
##### Les modèles séquence à séquence
Les modèles encodeur-décodeur (également appelés modèles séquence à séquence) utilisent les deux parties de l'architecture Transformer. À chaque étape, les couches d'attention de l'encodeur peuvent accéder à tous les mots de la phrase initiale, tandis que celles du décodeur ne peuvent accéder qu'aux mots situés avant un mot donné dans l'entrée.
-vertical-
Le pré-entraînement de ces modèles peut prendre différentes formes, mais il implique souvent le token masking.
Les modèles séquence à séquence sont particulièrement adaptés aux tâches de génération de nouvelles phrases à partir d'une entrée donnée, telles que le résumé, la traduction ou la réponse à des questions génératives.
-vertical-
Un guide rapide pour selectionner la bonne architecture selon vos tâches :
Task
Suggested Architecture
Examples
Text classification (sentiment, topic)
Encoder
BERT, RoBERTa
Text generation (creative writing)
Decoder
GPT, LLaMA
Translation
Encoder-Decoder
T5, BART
Summarization
Encoder-Decoder
BART, T5
Named entity recognition
Encoder
BERT, RoBERTa
Question answering (extractive)
Encoder
BERT, RoBERTa
Question answering (generative)
Encoder-Decoder or Decoder
T5, GPT
Conversational AI
Decoder
GPT, LLaMA
-vertical-
TP 4:
- A partir des données que vous avez récupérées, créez un dataset synthétique.
- Choississez l'architecture adaptée à votre tâche et trouvez un modèle qui correspond à votre tâche et à cette architecture.
-horizontal-
## Newsletter
-vertical-
1. Vrai ou faux: la réduction du taux d'apprentissage peut aider à éviter l'explosion des gradients pendant l'entraînement des réseaux de neurones.
2. Pourquoi est-ce que le réseau de neurone suivant est il linéaire sans activation ? couche d'entrée: `$w_1*x+w_2*x+b_1$` et couche cachée : `$w_3*x+b$`. Dessinez le réseau et écrivez sont équation.
3. Qu'est ce que la retropropagation (back propagation) ?
-vertical-
**Comprendre le mécanisme d'attention**
Avant de nous plonger dans l'attention multi-têtes, commençons par comprendre le mécanisme standard d'auto-attention, également appelé attention par produit scalaire échelonné.
À partir d'un ensemble de vecteurs d'entrée, l'auto-attention calcule les scores d'attention afin de déterminer le degré d'attention que chaque élément de la séquence doit accorder aux autres. Cette opération s'effectue à l'aide de trois matrices clés :
Requête (Q) – Représente la relation du mot actuel avec les autres.
Clé (K) – Représente les mots comparés.
Valeur (V) – Contient les représentations réelles des mots.
-vertical-
l'auto-attention est calculée comme suit :
$\text{Attention}(Q, K, V) = \text{softmax} \left( \frac{QK^T}{\sqrt{d_k}} \right) V$
-vertical-
**Qu'est-ce que l'attention multi-têtes ?**
L'attention multi-têtes étend l'auto-attention en divisant l'entrée en plusieurs têtes, permettant ainsi au modèle de capturer diverses relations et schémas.
Au lieu d'utiliser un seul ensemble de matrices Q, K, V, les plongements d'entrée sont projetés dans plusieurs ensembles (têtes), chacun ayant ses propres (Q, K, V).
-vertical-
**Transformation linéaire** : L’entrée
$X$ est projetée dans plusieurs sous-espaces de plus petite dimension à l’aide de différentes matrices de pondération.
$Q_i=XW^Q_i, K_i=XW^K_i, V_i=XW^V_i$
où $i$ désigne l’indice de la tête.
**Calcul indépendant de l’attention** : Chaque tête calcule indépendamment sa propre auto-attention à l’aide de la formule du produit scalaire mis à l’échelle.
**Concaténation** : Les sorties de toutes les têtes sont concaténées.
**Transformation linéaire finale** : Une matrice de pondération finale est appliquée pour transformer la sortie concaténée dans la dimension souhaitée.
-vertical-
**Pourquoi utiliser plusieurs têtes d'attention ?**
L'attention multi-têtes offre plusieurs avantages :
- Capture de différentes relations : différentes têtes s'intéressent à différents aspects de l'entrée.
- Améliore l'efficacité de l'apprentissage : en fonctionnant en parallèle, plusieurs têtes permettent un meilleur apprentissage des dépendances.
- Améliore la robustesse : le modèle ne repose pas sur un seul modèle d'attention, ce qui réduit le surapprentissage.
-vertical-
Il est très facile d'utiliser les transformers grâce à la bibliothèque de hugging face `transformers`
```
pipe = pipeline("text-classification")
pipe("This restaurant is awesome")
```
```
pipe = pipeline(model="FacebookAI/roberta-large-mnli")
pipe("This restaurant is awesome")
[{'label': 'NEUTRAL', 'score': 0.7313136458396912}]
```
-vertical-
La pipline réalise tout le travail du modèle :
-vertical-
**Prétraitement avec un tokenizer**
Comme d'autres réseaux neuronaux, les modèles Transformer ne peuvent pas traiter directement le texte brut. La première étape de notre pipeline consiste donc à convertir les entrées textuelles en nombres compréhensibles par le modèle. Pour ce faire, nous utilisons un tokenizer, qui se chargera de :
- Décomposer l'entrée en mots, sous-mots ou symboles (comme la ponctuation), appelés tokens ;
- Mapper chaque token à un entier ;
- Ajouter des entrées supplémentaires pouvant être utiles au modèle.
-vertical-
Tout ce prétraitement doit être effectué exactement de la même manière que lors du pré-entraînement du modèle. Nous devons donc d'abord télécharger ces informations depuis le Hub du modèle. Pour ce faire, nous utilisons la classe `AutoTokenizer` et sa méthode `from_pretrained()`. En utilisant le nom du point de contrôle de notre modèle, elle récupère automatiquement les données associées au tokenizer du modèle et les met en cache (elles ne sont donc téléchargées qu'à la première exécution du code ci-dessous).
Une fois le tokeniseur en place, nous pouvons lui transmettre directement nos phrases et obtenir un dictionnaire prêt à alimenter notre modèle ! Il ne reste plus qu'à convertir la liste des identifiants d'entrée en tenseurs.
-vertical-
Vous pouvez utiliser 🤗 Transformers sans vous soucier du framework ML utilisé comme backend ; il peut s'agir de PyTorch, de TensorFlow ou de Flax pour certains modèles. Cependant, les modèles Transformer n'acceptent que les tenseurs en entrée. Si vous entendez parler de tenseurs pour la première fois, vous pouvez les considérer comme des tableaux NumPy. Un tableau NumPy peut être un scalaire (0D), un vecteur (1D), une matrice (2D) ou avoir plusieurs dimensions. Il s'agit en fait d'un tenseur ; les tenseurs d'autres frameworks ML se comportent de manière similaire et sont généralement aussi simples à instancier que les tableaux NumPy.
-vertical-
```
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
```
```
{
'input_ids': tensor([
[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
])
}
```
La sortie elle-même est un dictionnaire contenant deux clés : input_ids et attention_mask. input_ids contient deux lignes d'entiers (une pour chaque phrase) qui sont les identifiants uniques des jetons de chaque phrase. Nous expliquerons ce qu'est attention_mask plus loin dans ce chapitre.
-vertical-
Nous pouvons télécharger notre modèle pré-entraîné de la même manière que nous l'avons fait avec notre tokenizer. 🤗 Transformers fournit une classe AutoModel qui possède également une méthode from_pretrained() :
```
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
```
-vertical-
**Un vecteur de grande dimension ?**
La sortie vectorielle du module Transformer est généralement volumineuse. Elle comporte généralement trois dimensions :
Taille du lot : nombre de séquences traitées simultanément (2 dans notre exemple).
Longueur de la séquence : longueur de la représentation numérique de la séquence (16 dans notre exemple).
Taille cachée : dimension vectorielle de chaque entrée du modèle.
On dit qu'il est « hautement dimensionnel » en raison de sa dernière valeur. La taille cachée peut être très importante (768 est courant pour les petits modèles, et peut atteindre 3072 ou plus pour les modèles plus grands).
-vertical-
```
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
```
```
torch.Size([2, 16, 768])
```
-vertical-
Post-traitement de la sortie
Les valeurs obtenues en sortie de notre modèle ne sont pas forcément logiques en elles-mêmes. Examinons-les :
```
print(outputs.logits)
```
```
tensor([[-1.5607, 1.6123],
[ 4.1692, -3.3464]], grad_fn=)
```
-vertical-
Notre modèle a prédit [-1,5607, 1,6123] pour la première phrase et [4,1692, -3,3464] pour la seconde. Il ne s'agit pas de probabilités, mais de logits, les scores bruts et non normalisés générés par la dernière couche du modèle. Pour être convertis en probabilités, ils doivent passer par une couche SoftMax (tous les modèles Transformers 🤗 génèrent des logits, car la fonction de perte pour l'apprentissage fusionne généralement la dernière fonction d'activation, comme SoftMax, avec la fonction de perte réelle, comme l'entropie croisée) :
-vertical-
##### Adapter un modèle à une tâche.
Le finetuning pourrait être considéré comme un sous-ensemble de la technique plus large de l’apprentissage par transfert : la pratique consistant à exploiter les connaissances qu’un modèle existant a déjà apprises comme point de départ pour l’apprentissage de nouvelles tâches.
L'intuition derrière le finetuning est qu'il est plus simple et moins coûteux d'affiner les capacités d'un modèle de base pré-entraîné, ayant déjà acquis des connaissances approfondies, que d'entraîner un nouveau modèle de toutes pièces pour cet objectif précis.
-vertical-
C'est particulièrement vrai pour les modèles d'apprentissage profond comportant des millions, voire des milliards de paramètres, comme les grands modèles de langage (LLM) qui ont pris de l'importance dans le domaine du traitement automatique du langage naturel (TALN) ou les réseaux de neurones convolutifs (RNC) et les transformateurs de vision (ViT) complexes utilisés pour des tâches de vision par ordinateur comme la classification, la détection d'objets ou la segmentation d'images.
-vertical-
Le finetuning utilise les pondérations d'un modèle pré-entraîné comme point de départ pour un entraînement ultérieur sur un ensemble de données plus restreint d'exemples reflétant plus directement les tâches et cas d'utilisation spécifiques du modèle.
Il implique généralement un apprentissage supervisé, mais peut également impliquer un apprentissage par renforcement, un apprentissage auto-supervisé ou un apprentissage semi-supervisé.
-vertical-
**Ajustement fin complet**
Le moyen le plus simple d'affiner le modèle consiste à mettre à jour l'ensemble du réseau neuronal. Cette méthodologie simple ressemble fondamentalement au processus d'entrainement : les seules différences fondamentales entre les processus d'ajustement fin complet et d'entraînement (ou pré-entraînement) résident dans le jeu de données utilisé et dans l'état initial des paramètres du modèle.
-vertical-
**Réglage fin optimisé des paramètres (PEFT)**
Le réglage fin complet, tout comme le processus de pré-apprentissage auquel il ressemble, est très exigeant en termes de calcul. Pour les modèles d'apprentissage profond modernes comportant des centaines de millions, voire des milliards de paramètres, son coût est souvent prohibitif et peu pratique.
-vertical-
Le réglage fin optimisé des paramètres (PEFT) englobe diverses méthodes visant à réduire le nombre de paramètres entraînables à mettre à jour afin d'adapter efficacement un modèle pré-entraîné volumineux à des applications spécifiques en aval. Ce faisant, le PEFT réduit considérablement les ressources de calcul et l'espace mémoire nécessaires pour produire un modèle optimisé efficacement. Les méthodes PEFT se sont souvent avérées plus stables que les méthodes de réglage fin complet, notamment pour les cas d'utilisation du TALN.
-vertical-
Dans les PEFTs majeurs on note:
- le partial finetuning qui consistent au gel de certains paramètres (habituellement les couches internes)
- le finetuning additif où l'on ajoute des couches supplémentaires qui seront apprises sur le nouveau jeu de données. On peut également utiliser le fine tuning additif pour l'entraînement d'_Adapters_.
- La reparametrisation (notamment les LoRa)
-vertical-
Transformers fournit une classe Trainer pour vous aider à affiner les modèles pré-entraînés fournis sur votre jeu de données. Une fois le prétraitement des données effectué dans la section précédente, il ne vous reste plus que quelques étapes pour définir le Trainer. Le plus difficile sera probablement de préparer l'environnement pour l'exécution de Trainer.train(), car il sera très lent sur un processeur. Si vous n'avez pas de GPU configuré, vous pouvez accéder à des GPU ou TPU gratuits sur Google Colab.
-vertical-
Il va falloir d'abord transformer les données pour les rendre utilisables par la pipeline:
Pour prétraiter l'ensemble de données, nous devons convertir le texte en nombres compréhensibles par le modèle. Comme on l'a vu, cette opération s'effectue à l'aide d'un tokeniseur. Nous pouvons lui fournir une phrase ou une liste de phrases, ce qui nous permet de tokeniser directement toutes les premières et secondes phrases de chaque paire, comme suit :
```
from transformers import AutoTokenizer
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
tokenized_sentences_1 = tokenizer(raw_datasets["train"]["sentence1"])
tokenized_sentences_2 = tokenizer(raw_datasets["train"]["sentence2"])
```
-vertical-
```
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
-vertical-
La première étape avant de définir notre Trainer consiste à définir une classe TrainingArguments qui contiendra tous les hyperparamètres utilisés par le Trainer pour l'entraînement et l'évaluation. Le seul argument à fournir est un répertoire où le modèle entraîné sera enregistré, ainsi que les points de contrôle. Pour le reste, vous pouvez conserver les valeurs par défaut, ce qui devrait suffire pour un réglage fin de base.
```
from transformers import TrainingArguments
training_args = TrainingArguments("test-trainer")
```
-vertical-
On veut ensuite charger notre modèle
```
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
```
pour pourvoir le donner au Trainer
```
from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
```
-vertical-
Et pour lancer le finetuning, il suffit de lancer
`trainer.train()`
-vertical-
Cela lancera le finetuning (qui devrait prendre quelques minutes sur un GPU) et signalera la perte d'entraînement toutes les 500 étapes. Cependant, cela ne vous indiquera pas les performances de votre modèle. En effet, :
1. Nous n'avons pas indiqué au formateur d'effectuer une évaluation pendant l'entraînement en définissant eval_strategy dans TrainingArguments sur « steps » (évaluation à chaque eval_steps) ou « epoch » (évaluation à la fin de chaque époque).
2. Nous n'avons pas fourni au formateur de fonction compute_metrics() pour calculer une métrique pendant cette évaluation (sinon, l'évaluation aurait simplement affiché la perte, ce qui n'est pas un chiffre très intuitif).
-vertical-
### Point Bonne pratique
#### Commits conventionnels
Les commits sur Git respectent certaines conventions qui sont listés sur le site des [commit conventionnels](https://www.conventionalcommits.org/en/v1.0.0/)
Ils utilisent des prefix qui permettent de comprendre de quoi le commit est question
-vertical-
Le commit contient les éléments structurels suivants, afin de communiquer l'intention aux utilisateurs de votre bibliothèque :
- fix: un commit de type fix corrige un bug dans votre base de code (corrélation avec PATCH dans le contrôle de version sémantique).
- feat: un commit de type feat introduit une nouvelle fonctionnalité dans la base de code (équivalent de MINOR dans le contrôle de version sémantique).
- BREAKING CHANGE : un commit comportant un pied de page BREAKING CHANGE : ou ajoutant un « !» après le type/la portée, introduit un changement d'API de rupture (corrélation avec MAJEUR dans le contrôle de version sémantique). Un BREAKING CHANGE peut faire partie de tout type de commit.
- Les types autres que fix: et feat: sont autorisés. Par exemple, @commitlint/config-conventional (selon la convention Angular) recommande build:, chore:, ci:, docs:, style:, refactor:, perf:, test:, etc.
-vertical-
**Examples**
→ Commit message with description and breaking change footer
```
feat: allow provided config object to extend other configs
BREAKING CHANGE: `extends` key in config file is now used for extending other config files
```
→ Commit message with ! to draw attention to breaking change
```
feat!: send an email to the customer when a product is shipped
```
→ Commit message with scope and ! to draw attention to breaking change
```
feat(api)!: send an email to the customer when a product is shipped
```
-vertical-
### Petit Glossaire des personnalités à connaître de l'informatique
- Tim Berners Lee
- Claude Shannon
- Guido Van Rossum
- Vaswani
-vertical-
Quizz 4
-vertical-
1. A quoi correspond l'auto attention ? Comment est-elle calculée ?
2. Pourquoi finetune t-on des modèles ?
3. Ecrivez un commit qui répare une fonctionnalité d'envoi de mail mal fonctionnelle.
-vertical-
TP 4:
- A partir des données que vous avez récupérées, créez un dataset synthétique.
- Choississez l'architecture adaptée à votre tâche et trouvez un modèle qui correspond à votre tâche et à cette architecture.
-vertical-
### TP 5
- Finetuner le modèle pretrained qui correspond le plus à vos données grâce au trainer d'hugging face
 -vertical-
Il y a plusieurs loss utilisées pour les problèmes de regression linéaire :
-vertical-
Il y a plusieurs loss utilisées pour les problèmes de regression linéaire :
 -vertical-
##### 1.A.iii. La descente de gradient
La descente de gradient est une technique mathématique qui permet de déterminer de manière itérative les pondérations et les biais permettant d'obtenir le modèle présentant la perte la plus faible. La descente de gradient permet de déterminer les pondérations et les biais les plus adaptés en répétant le processus suivant pour un nombre d'itérations défini par l'utilisateur.
-vertical-
Le modèle commence l'entraînement avec des pondérations et des biais aléatoires proches de zéro, puis répète les étapes suivantes :
1. Calculer la perte avec les pondérations et les biais actuels.
2. Déterminer la direction dans laquelle déplacer les pondérations et les biais pour réduire la perte.
3. Déplacer légèrement les valeurs de pondération et de biais dans la direction qui réduit la perte.
4. Revenir à l'étape 1 et répéter le processus jusqu'à ce que le modèle ne puisse plus réduire la perte.
-vertical-
-vertical-
##### 1.A.iii. La descente de gradient
La descente de gradient est une technique mathématique qui permet de déterminer de manière itérative les pondérations et les biais permettant d'obtenir le modèle présentant la perte la plus faible. La descente de gradient permet de déterminer les pondérations et les biais les plus adaptés en répétant le processus suivant pour un nombre d'itérations défini par l'utilisateur.
-vertical-
Le modèle commence l'entraînement avec des pondérations et des biais aléatoires proches de zéro, puis répète les étapes suivantes :
1. Calculer la perte avec les pondérations et les biais actuels.
2. Déterminer la direction dans laquelle déplacer les pondérations et les biais pour réduire la perte.
3. Déplacer légèrement les valeurs de pondération et de biais dans la direction qui réduit la perte.
4. Revenir à l'étape 1 et répéter le processus jusqu'à ce que le modèle ne puisse plus réduire la perte.
-vertical-
 -vertical-
###### 1.A.iv. La descente de gradient : un exemple
Concrètement, on peut parcourir les étapes de descente de gradient en utilisant un petit ensemble de données avec sept exemples de poids d'une voiture et de sa consommation d'essence :
-vertical-
###### 1.A.iv. La descente de gradient : un exemple
Concrètement, on peut parcourir les étapes de descente de gradient en utilisant un petit ensemble de données avec sept exemples de poids d'une voiture et de sa consommation d'essence :
 -vertical-
Vous pouvez constater que la perte diminue considérablement au cours des premières itérations, puis diminue progressivement avant de s'aplatir vers la 1 000e itération. Après 1 000 itérations, nous pouvons être presque certains que le modèle a convergé.
-vertical-
##### 1.A.vi. Paramètres et Hyperparamètres
Les paramètres d'un modèles (1B, 7B, ...), c'est en fait le nombres de poids et de biais du modèles. Ce sont toutes les parties "apprisent" par le modèle.
Ses Hyperparamètres, ce sont les parties choisies par le developpeur. On note quelques hyperparamètres importants:
- la taille de batch
- le taux d'apprentissage (learning rate)
- le nombre d'époques
-vertical-
**Taux d'apprentissage**
Le taux d'apprentissage influence la rapidité de convergence du modèle.
La différence entre les anciens paramètres du modèle et les nouveaux paramètres du modèle est proportionnelle à la pente de la fonction de perte. Par exemple, si la pente est importante, le modèle effectue un grand pas. Si elle est petite, il faut faire un petit pas. Par exemple, si l'ampleur de la pente est de 2,5 et que le taux d'apprentissage est de 0,01, le modèle modifie le paramètre de 0,025.
-vertical-
Le taux d'apprentissage idéal aide le modèle à converger en un nombre raisonnable d'itérations.
Si le taux d'apprentissage est trop faible, la convergence du modèle peut prendre beaucoup de temps. Toutefois, si le taux d'apprentissage est trop élevé, le modèle ne converge jamais, mais oscille autour des pondérations et des biais qui minimisent la perte. L'objectif est de choisir un taux d'apprentissage qui n'est ni trop élevé ni trop faible pour que le modèle converge rapidement.
-vertical-
Taux d'apprentissage trop faible :
-vertical-
Vous pouvez constater que la perte diminue considérablement au cours des premières itérations, puis diminue progressivement avant de s'aplatir vers la 1 000e itération. Après 1 000 itérations, nous pouvons être presque certains que le modèle a convergé.
-vertical-
##### 1.A.vi. Paramètres et Hyperparamètres
Les paramètres d'un modèles (1B, 7B, ...), c'est en fait le nombres de poids et de biais du modèles. Ce sont toutes les parties "apprisent" par le modèle.
Ses Hyperparamètres, ce sont les parties choisies par le developpeur. On note quelques hyperparamètres importants:
- la taille de batch
- le taux d'apprentissage (learning rate)
- le nombre d'époques
-vertical-
**Taux d'apprentissage**
Le taux d'apprentissage influence la rapidité de convergence du modèle.
La différence entre les anciens paramètres du modèle et les nouveaux paramètres du modèle est proportionnelle à la pente de la fonction de perte. Par exemple, si la pente est importante, le modèle effectue un grand pas. Si elle est petite, il faut faire un petit pas. Par exemple, si l'ampleur de la pente est de 2,5 et que le taux d'apprentissage est de 0,01, le modèle modifie le paramètre de 0,025.
-vertical-
Le taux d'apprentissage idéal aide le modèle à converger en un nombre raisonnable d'itérations.
Si le taux d'apprentissage est trop faible, la convergence du modèle peut prendre beaucoup de temps. Toutefois, si le taux d'apprentissage est trop élevé, le modèle ne converge jamais, mais oscille autour des pondérations et des biais qui minimisent la perte. L'objectif est de choisir un taux d'apprentissage qui n'est ni trop élevé ni trop faible pour que le modèle converge rapidement.
-vertical-
Taux d'apprentissage trop faible :
 -vertical-
Taux d'apprentissage trop élevé :
-vertical-
Taux d'apprentissage trop élevé :
 -vertical-
**Taille de batch (ou lot)**
La taille de lot est le nombre d'exemples que le modèle traite avant de mettre à jour ses poids et ses biais. Avec des jeux de données très grand, il n'est pas pratique d'utiliser tout le jeu de données avant de mettre à jour les poids : c'est trop couteux.
Deux techniques courantes pour obtenir le bon gradient en moyenne sans avoir à examiner chaque exemple de l'ensemble de données avant de mettre à jour les poids et le biais sont la descente aléatoire (stochastique) du gradient et la descente stochastique du gradient en mini-lot.
-vertical-
-vertical-
**Taille de batch (ou lot)**
La taille de lot est le nombre d'exemples que le modèle traite avant de mettre à jour ses poids et ses biais. Avec des jeux de données très grand, il n'est pas pratique d'utiliser tout le jeu de données avant de mettre à jour les poids : c'est trop couteux.
Deux techniques courantes pour obtenir le bon gradient en moyenne sans avoir à examiner chaque exemple de l'ensemble de données avant de mettre à jour les poids et le biais sont la descente aléatoire (stochastique) du gradient et la descente stochastique du gradient en mini-lot.
-vertical-
 On peut observer que parfois la loss remonte.
-vertical-
Avec une descente de gradient stochastique par mini-lot, on choisi une taille de lot.
Pour un nombre de points de données N
, la taille de lot peut être n'importe quel nombre supérieur à 1 et inférieur à N
.Le modèle choisit les exemples inclus dans chaque lot de manière aléatoire (stochastique), calcule la moyenne de leurs gradients, puis met à jour les poids et le biais une fois par itération.
-vertical-
Le nombre d'exemples pour chaque lot dépend de l'ensemble de données et des ressources de calcul disponibles. En général, les petites tailles de lot se comportent comme la descente du gradient stochastique, tandis que les tailles de lot plus importantes se comportent comme la descente du gradient sur l'ensemble du lot.
-vertical-
**Époques (Epoch)**
Lors de l'entraînement, une époque signifie que le modèle a traité chaque exemple de l'ensemble d'entraînement une fois. Par exemple, étant donné un ensemble d'entraînement de 1 000 exemples et une taille de mini-lot de 100 exemples, le modèle nécessitera 10 itérations pour terminer une époque.
L'entraînement nécessite généralement de nombreuses époques. Autrement dit, le système doit traiter chaque exemple de l'ensemble d'entraînement plusieurs fois.
-vertical-
Le nombre d'époques est un hyperparamètre que vous définissez avant le début de l'entraînement du modèle. Dans de nombreux cas, vous devrez tester le nombre d'époques nécessaires pour que le modèle converge. En général, un nombre d'époques plus élevé produit un meilleur modèle, mais l'entraînement prend plus de temps.
-vertical-
#### 1.B. Regression Logistique
La regression linéaire est efficace pour prédire des valeurs. Avec certains types de données, on va plutôt vouloir calculer des probabilités qu'un element soit ou non d'un type, d'une classe.
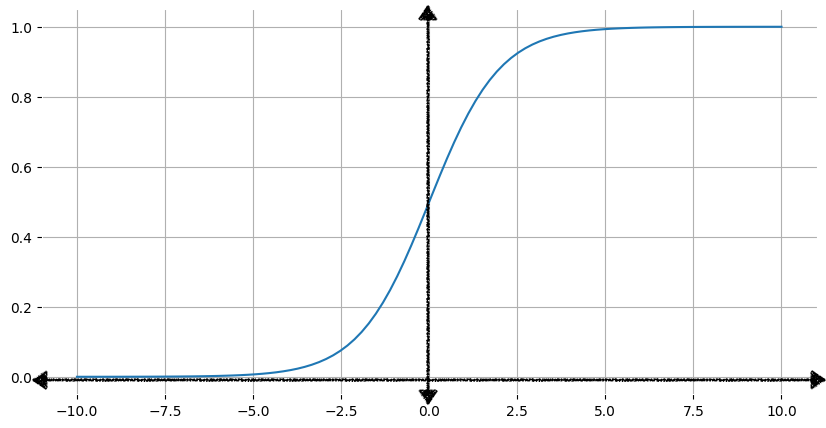
Pour ça, il suffit de transformer les valeurs de la regression linéaire Pour la conditionner à donner des résultats entre 0 et 1.
-vertical-
La fonction qu'on utilise pour ça est la fonction suivante :
On peut observer que parfois la loss remonte.
-vertical-
Avec une descente de gradient stochastique par mini-lot, on choisi une taille de lot.
Pour un nombre de points de données N
, la taille de lot peut être n'importe quel nombre supérieur à 1 et inférieur à N
.Le modèle choisit les exemples inclus dans chaque lot de manière aléatoire (stochastique), calcule la moyenne de leurs gradients, puis met à jour les poids et le biais une fois par itération.
-vertical-
Le nombre d'exemples pour chaque lot dépend de l'ensemble de données et des ressources de calcul disponibles. En général, les petites tailles de lot se comportent comme la descente du gradient stochastique, tandis que les tailles de lot plus importantes se comportent comme la descente du gradient sur l'ensemble du lot.
-vertical-
**Époques (Epoch)**
Lors de l'entraînement, une époque signifie que le modèle a traité chaque exemple de l'ensemble d'entraînement une fois. Par exemple, étant donné un ensemble d'entraînement de 1 000 exemples et une taille de mini-lot de 100 exemples, le modèle nécessitera 10 itérations pour terminer une époque.
L'entraînement nécessite généralement de nombreuses époques. Autrement dit, le système doit traiter chaque exemple de l'ensemble d'entraînement plusieurs fois.
-vertical-
Le nombre d'époques est un hyperparamètre que vous définissez avant le début de l'entraînement du modèle. Dans de nombreux cas, vous devrez tester le nombre d'époques nécessaires pour que le modèle converge. En général, un nombre d'époques plus élevé produit un meilleur modèle, mais l'entraînement prend plus de temps.
-vertical-
#### 1.B. Regression Logistique
La regression linéaire est efficace pour prédire des valeurs. Avec certains types de données, on va plutôt vouloir calculer des probabilités qu'un element soit ou non d'un type, d'une classe.
Pour ça, il suffit de transformer les valeurs de la regression linéaire Pour la conditionner à donner des résultats entre 0 et 1.
-vertical-
La fonction qu'on utilise pour ça est la fonction suivante :
 -vertical-
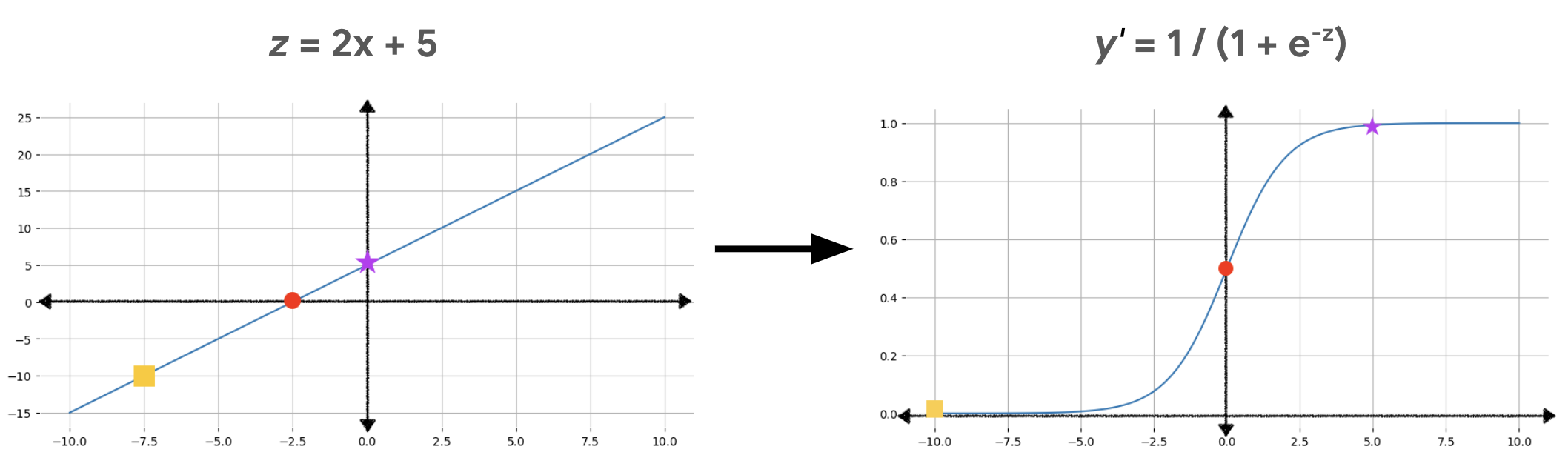
Pour faire la transformation, on a simplement à mettre la valeur de notre régression linéaire $z$ dans la formule de la fonction : $\frac{1}{1+e^{-x}}$
-vertical-
Pour faire la transformation, on a simplement à mettre la valeur de notre régression linéaire $z$ dans la formule de la fonction : $\frac{1}{1+e^{-x}}$
 -vertical-
La regression logistique a ses propres fonctions de perte que l'on appelle log loss.
Pour faire de la classification, c'est la regression logistique que l'on transforme en prédictions binaires en choisissant un seuil de classification.
-vertical-
Quizz 2
-vertical-
Quizz 2
-vertical-
La regression logistique a ses propres fonctions de perte que l'on appelle log loss.
Pour faire de la classification, c'est la regression logistique que l'on transforme en prédictions binaires en choisissant un seuil de classification.
-vertical-
Quizz 2
-vertical-
Quizz 2
 -vertical-
Pour quitter la linéarité, on va vouloir ajouter des modifications des résultats au milieu de notre calcul.
On va ajouter une couche "cachées" constituées de "neurones" entre les entrées et le résultat
-vertical-
Pour quitter la linéarité, on va vouloir ajouter des modifications des résultats au milieu de notre calcul.
On va ajouter une couche "cachées" constituées de "neurones" entre les entrées et le résultat
 -vertical-
Sans modifier plus que ça notre réseau, on ne peut pas calculer de non-linéarité parceque le résultat final correpond toujours à la somme de $(x_1w_1+b_1)w_2+b_2=(w_2*w_1)*x_1+w_2b_1+b_2$
On va vouloir casser la linéarité en applicant des fonctions non linéaire à la sortie de chaque couche.
On a déjà vu une fonction non linéaire pour la régression logistique : la fonction sigmoïde.
-vertical-
Maintenant que nous avons ajouté une fonction d'activation, l'ajout de couches a plus d'impact. L'empilement de non-linéarités nous permet de modéliser des relations très complexes entre les entrées et les sorties prévues. En résumé, chaque couche apprend une fonction plus complexe et de niveau supérieur par rapport aux entrées brutes.
-vertical-
**Fonction d'activation**
On appelle la fonction qu'on met en sortie du neurone la fonction d'activation. On peut utiliser plusieurs types de fonctions différentes : les sigmoïde, les ReLU, ...
-vertical-
Sauf que maintenant qu'on a plus de linéarité, comment est ce qu'on va pouvoir calculer le gradient de notre fonction ?
→ on va utiliser la retropropagation
-vertical-
Sans modifier plus que ça notre réseau, on ne peut pas calculer de non-linéarité parceque le résultat final correpond toujours à la somme de $(x_1w_1+b_1)w_2+b_2=(w_2*w_1)*x_1+w_2b_1+b_2$
On va vouloir casser la linéarité en applicant des fonctions non linéaire à la sortie de chaque couche.
On a déjà vu une fonction non linéaire pour la régression logistique : la fonction sigmoïde.
-vertical-
Maintenant que nous avons ajouté une fonction d'activation, l'ajout de couches a plus d'impact. L'empilement de non-linéarités nous permet de modéliser des relations très complexes entre les entrées et les sorties prévues. En résumé, chaque couche apprend une fonction plus complexe et de niveau supérieur par rapport aux entrées brutes.
-vertical-
**Fonction d'activation**
On appelle la fonction qu'on met en sortie du neurone la fonction d'activation. On peut utiliser plusieurs types de fonctions différentes : les sigmoïde, les ReLU, ...
-vertical-
Sauf que maintenant qu'on a plus de linéarité, comment est ce qu'on va pouvoir calculer le gradient de notre fonction ?
→ on va utiliser la retropropagation
 -vertical-
**Prétraitement avec un tokenizer**
Comme d'autres réseaux neuronaux, les modèles Transformer ne peuvent pas traiter directement le texte brut. La première étape de notre pipeline consiste donc à convertir les entrées textuelles en nombres compréhensibles par le modèle. Pour ce faire, nous utilisons un tokenizer, qui se chargera de :
- Décomposer l'entrée en mots, sous-mots ou symboles (comme la ponctuation), appelés tokens ;
- Mapper chaque token à un entier ;
- Ajouter des entrées supplémentaires pouvant être utiles au modèle.
-vertical-
-vertical-
**Prétraitement avec un tokenizer**
Comme d'autres réseaux neuronaux, les modèles Transformer ne peuvent pas traiter directement le texte brut. La première étape de notre pipeline consiste donc à convertir les entrées textuelles en nombres compréhensibles par le modèle. Pour ce faire, nous utilisons un tokenizer, qui se chargera de :
- Décomposer l'entrée en mots, sous-mots ou symboles (comme la ponctuation), appelés tokens ;
- Mapper chaque token à un entier ;
- Ajouter des entrées supplémentaires pouvant être utiles au modèle.
-vertical-